[TiDB Usage Environment] Production Environment
[TiDB Version] v6.1.0
[Reproduction Path] None
[Encountered Problem: Phenomenon and Impact]
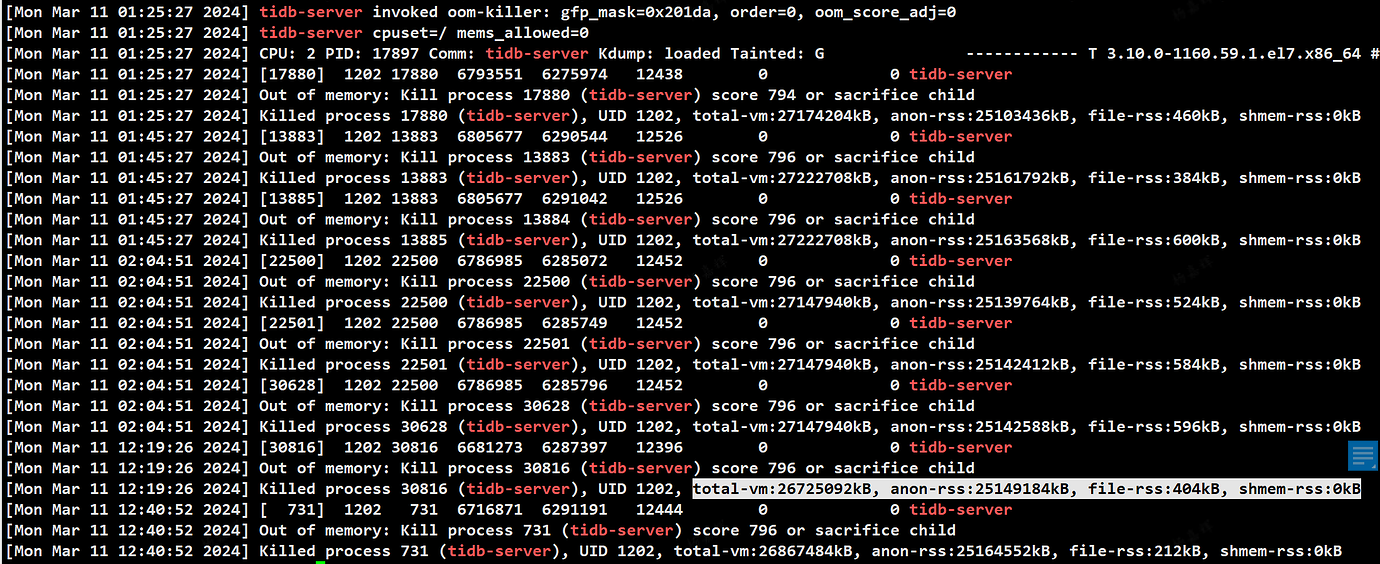
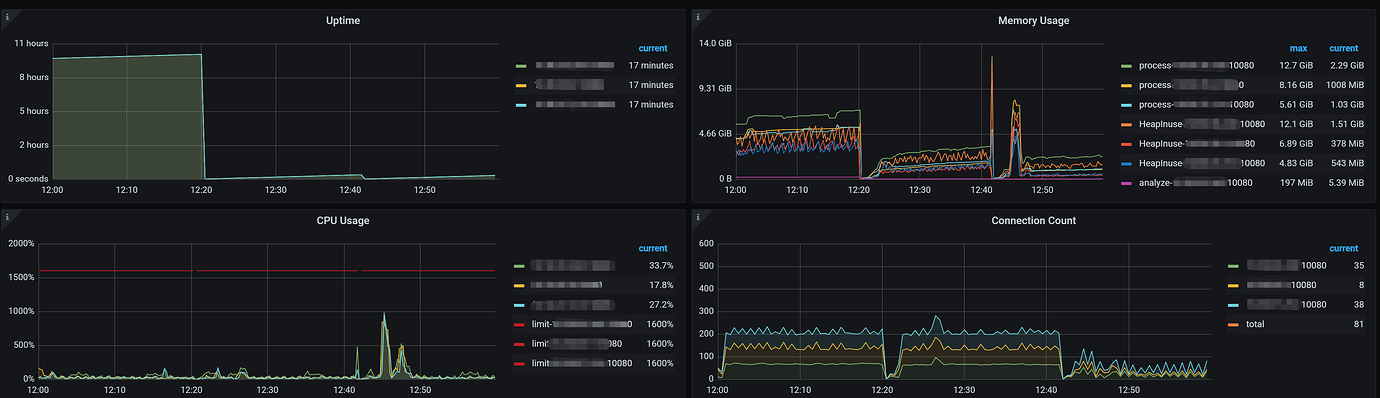
Help needed: All three TiDB nodes experienced OOM simultaneously, with the actual physical machine memory usage at a maximum of 50%, and the maximum memory consumption around 13GB (TiDB and PB are deployed on the same machine). In dmesg -T|grep tidb-server, anon-rss used about 25GB. anon-rss indicates the resident set size (RSS) of anonymous memory (i.e., memory not mapped to files). Could this be caused by a memory leak?
[Resource Configuration]
TiDB nodes: 16 cores, 32GB
[Attachments: Screenshots/Logs/Monitoring]
Try grepping “expensive_query” in the tidb.log to see if you can find the SQL before the node OOM restart, and combine it with the Dashboard for further analysis.
Mixed deployment is not as good as independent deployment on a single node (scheduling mixed three replicas is relatively difficult, requiring consideration of resource isolation, which is actually very challenging).
Check if there is an OOM keyword in the TiDB logs, and also check the memory usage in the system info section of the overview in Grafana. Additionally, have you performed NUMA resource isolation?
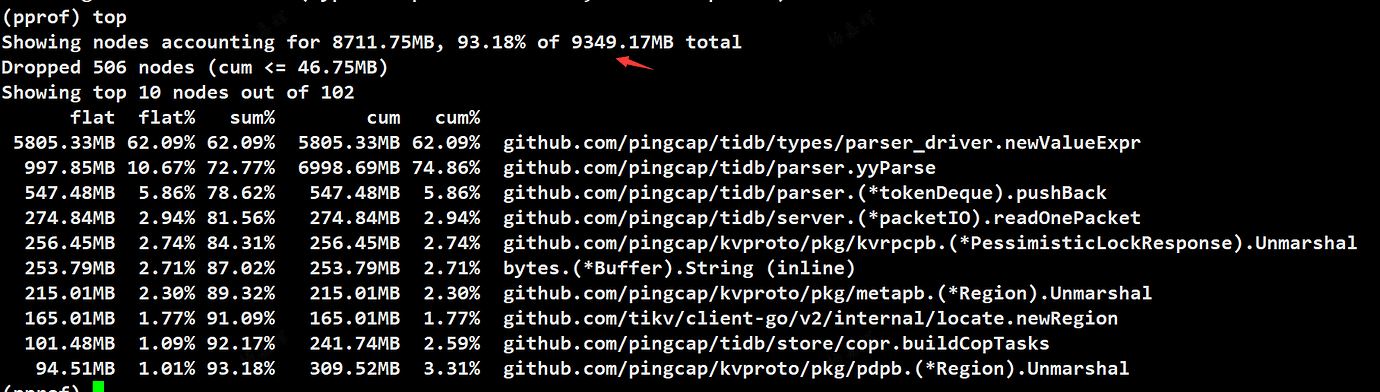
It is recommended to check what the SQL statements were at that time. After all, from your dump, it seems that a large number of SQL statements were parsed, leading to the above being called frantically and many objects being created. This resulted in memory overload.
Additionally, the fact that all three machines crashed simultaneously does not indicate a memory leak. If it were a memory leak, each TiDB instance would eventually crash, but the likelihood of them crashing simultaneously is very low. Simultaneous crashes are more likely due to all three machines receiving a large number of SQL statements at the same time, causing a delay in garbage collection.
In the logs, there are many identical delete SQL operations under expensive_query, but these SQLs appear after the OOM restart, not before the OOM. If there are a large number of requests, the QPS does not show significant changes around 12:20 PM on the 11th.
The NUMA resource isolation you mentioned doesn’t seem to exist. I checked the NUMA memory in the node monitoring again, and it seems that the OOM is due to insufficient memory.
Three nodes experienced OOM simultaneously, it doesn’t seem to be caused by a single large SQL. Check the cluster configuration with tiup cluster display XXXX and tiup cluster show-config XXXX.
Check if there is a numa_node keyword in the tiup cluster edit-config, and also use numactl --hardware to check the NUMA situation of your machine.
For example, my machine has 192G of memory and two NUMA nodes. It has PD and tidb-server deployed on it. The PD numa_node is bound to 0, and the tidb-server numa_node is bound to 1. Therefore, the maximum memory that tidb-server can use is 96G. Even if there is remaining memory in numa_node 0 where PD is located, tidb-server will not use it. If it exceeds 96G of memory, it will be killed by OOM.