Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: kv离线节点无法移除(tidb6.1)
Production environment TiDB 6.1, with PD, TiDB, and KV each deployed on 3 nodes. One KV node went offline automatically and could not be restarted. At the top of the hour, database performance drops for about 10 minutes. Used tiup cluster scale-in to forcibly remove the offline node from the cluster, executed tiup cluster prune to clean up, and used tiup cluster display to check node information, confirming the offline node was removed. However, the dashboard still shows it as offline.
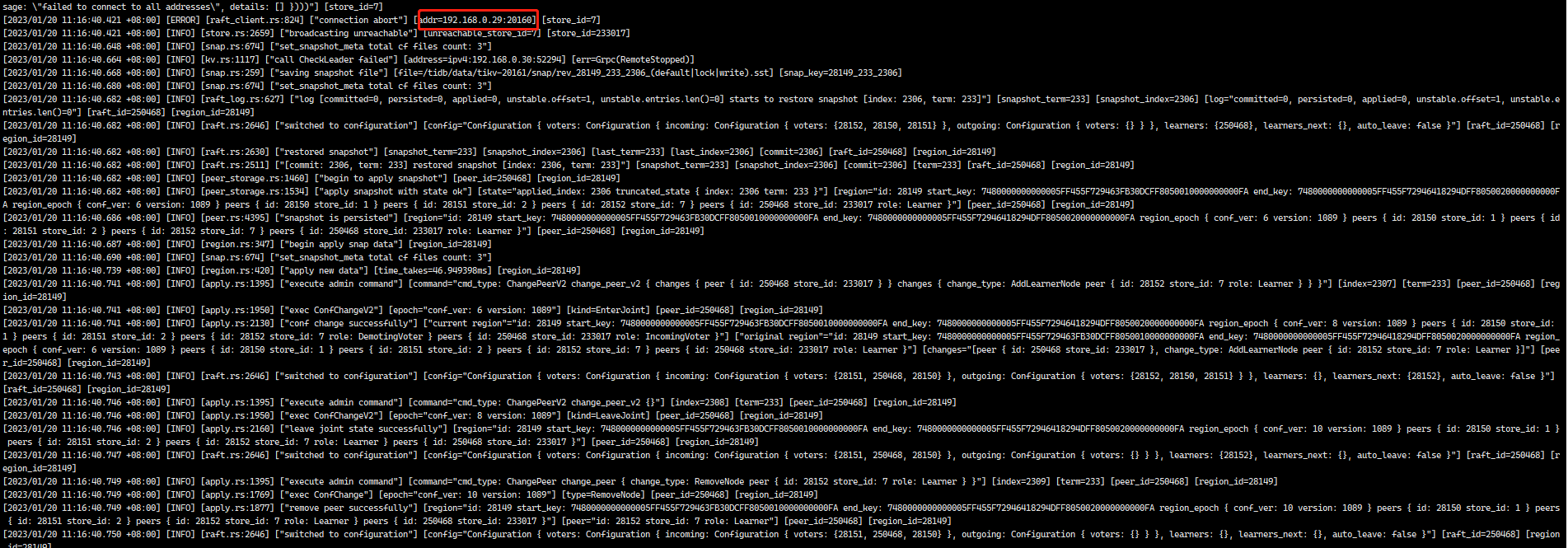
Re-deployed KV on the original offline server (system reinstalled), but encountered installation failure with port 20160. Changed the port to 20161/20181 and successfully redeployed. Checking the KV logs, the previously removed node still appears and reports errors. Error logs are as follows:
Using tiup cluster display to check current node information:
Viewing node information on the web:
The offline node cannot be removed. Any guidance would be greatly appreciated!
Could you explain in more detail the steps you took when going offline? Did you wait for TiKV to evict all the leaders?
By default, tiup only waits for 5 minutes when evicting leaders. If the data volume is too large, it is possible that even though the scale-in process has ended (with an error reported), the leader eviction is still being executed in the background.
You can execute this command to check if the node status is normal:
tiup ctl:v6.1.0 pd store --jq '.stores[] | .store | {address, version, state_name}'
Check with pd ctl to see if there is any information about nodes (stores) that have not been taken offline.
The offline node went offline on December 17th. It was discovered that the database performance drops at the top of the hour, lasting about 10 minutes. Upon checking the database, it was found that a KV node was offline and could not be started. Using tiup cluster scale-in, the offline node was forcibly removed from the cluster. After about ten minutes, tiup cluster prune was executed. However, upon checking, the offline node was still present. Several hours later, the cleanup was executed again, but the offline node was still there.
I think the problem is that the tidb-server process is not running. You can check if the process is running using the ps command. If it is not running, you can start it using the systemctl start tidb command.
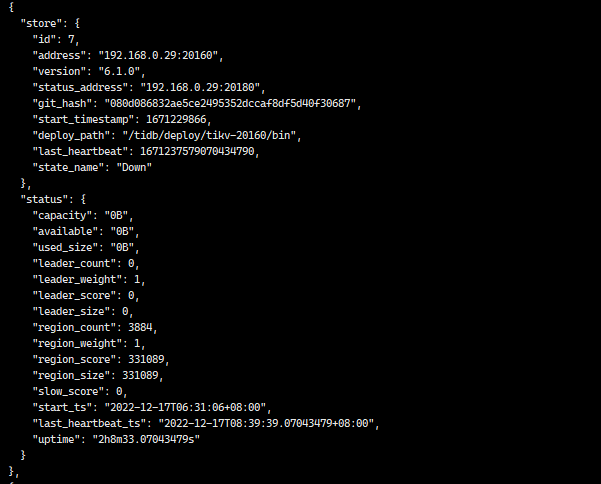
The uptime seems to indicate that it is still in use recently. Can you log in to the TiKV node and check the process with ps to see if it is still running?
Additionally, the node status is down, not tombstone. I suspect that there might still be a leader that hasn’t been transferred before you forcibly deleted it.
Try deleting the store with store_id. Be careful not to get the id wrong.
First, the node malfunctioned and couldn’t start up. Then, the node was forcibly deleted, and the system was reinstalled.
The process is gone, I reinstalled the system. The previous port number was 20160, and I added this 20161 later.
The meanings of each state are shown in the picture. It is recommended not to directly delete the store for now, as there is a risk of losing regions. (Although you have reinstalled the system, the TiKV data is most likely on the data disk, not the system disk, so the data is still there after reinstallation. This is also why you encountered errors when trying to install using the original port.)
The one with id 7, this one is correct, right?
I checked the disk usage after reinstalling the system, and the disk space has been freed up.
Listen to the expert, first check if there are any regions with missing replicas. Once everything is normal, proceed with the deletion. However, your node went offline on the 17th, which was several days ago, so the replicas should have already been replenished.
After executing the delete operation, the status changed.
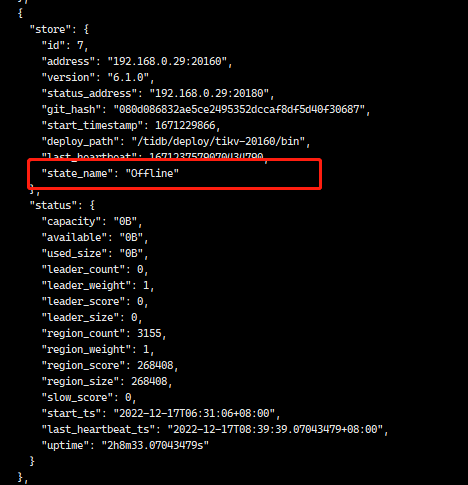
The previous node still appears in the logs.
After performing the delete operation, the status changed.
The previous node still appears in the logs.
Wait and see. In the meantime, monitor the region information of store 7.
The offline phase is actually transferring the leader to other nodes, but since you have already deleted the data, I’m not sure if it can be transferred normally. Execute this on pd-ctl to see if there is any region information left:
region store 7
Also execute region check down-peer to see if the status of all regions is normal.