Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: es集群重启某节点后unassigned
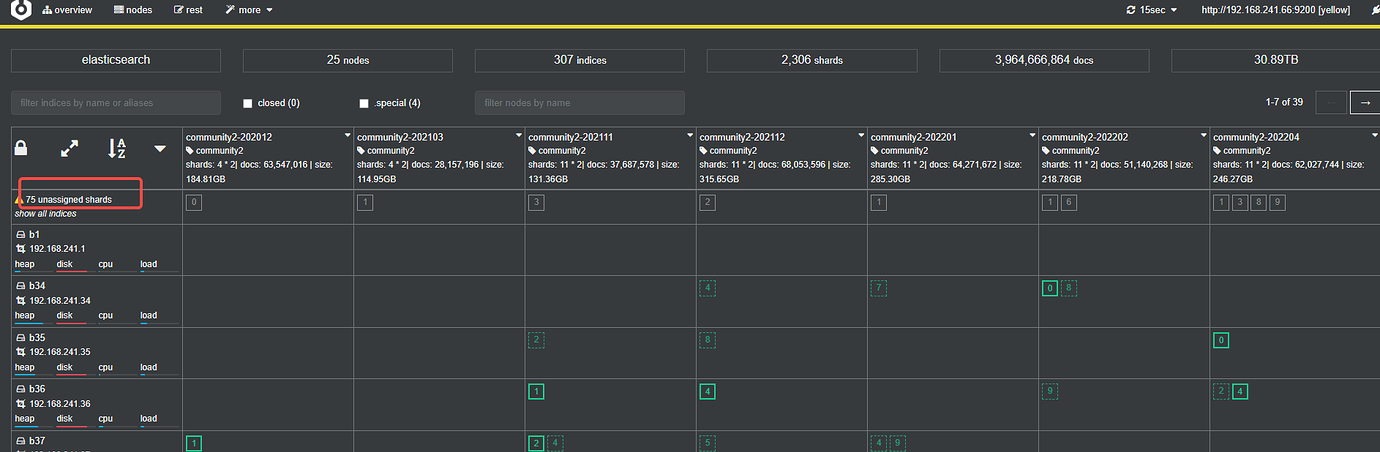
After restarting a node in the ES cluster, many shards on the node became unassigned.
The node was restarted only to add some configurations (MinIO for ES snapshot storage, which should be unrelated since it has been done on other nodes without issues).
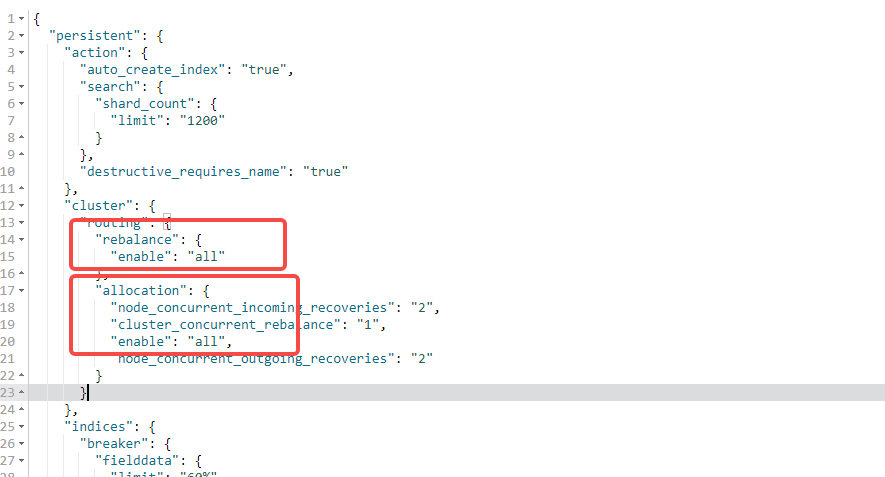
Cluster allocation and rebalance are both set to all.
The explanation is as follows:
Replicas are not allowed to be allocated if the default node disk usage exceeds 85%. You can check the node disk usage.
I tried increasing this parameter to 95%, but it didn’t work. It shouldn’t be this issue. If it were this issue, the explain command would directly report insufficient disk space.
That might be because the total number of shards is greater than the number of nodes. Run GET _cat/shards?h=index,shard,prirep,state,unassigned.reason to confirm.
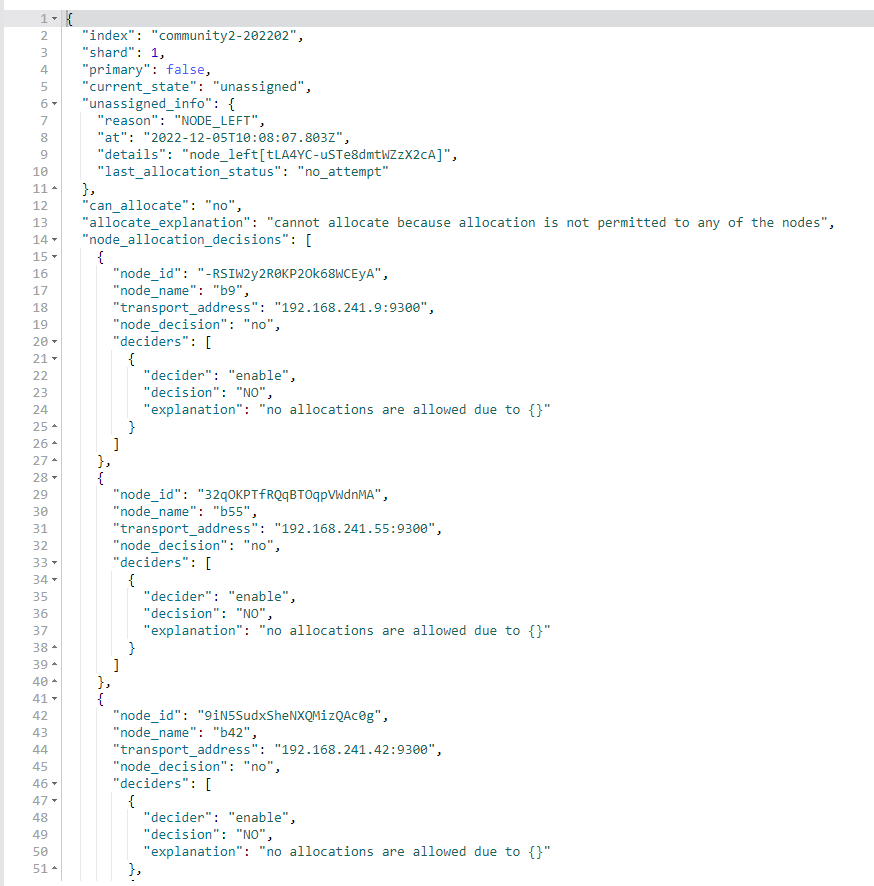
All are UNASSIGNED NODE_LEFT
It shouldn’t be this issue. Our cluster has 22 data nodes, and the node with the most shards only has 11 shards.
If each shard has a replica, that means there are 22 shards. If one node goes down, there will be no place to store the shard.
This node has already started.
It shouldn’t be an issue as long as the primary and secondary replicas are not on the same shard; they can exist on the same node. There is still quite a bit of unallocated space.
Did you restart the B1 node? It looks like the B1 node hasn’t been assigned any shards in the picture.
Yes. I see that the data is on B1, but it’s just not being allocated. Strange.
That means there is a problem. The cluster thinks it has left, so it reports an error that the shard cannot be allocated. For specific reasons why it is not allocated, you can check the es.log of node B1.
I have checked the logs for both b1 and master, and there don’t seem to be any abnormal prompts.
[2022-12-06T10:37:37,704][WARN ][o.e.l.LicenseService ] [b1]
LICENSE [EXPIRED] ON [WEDNESDAY, FEBRUARY 21, 2018]. IF YOU HAVE A NEW LICENSE, PLEASE UPDATE IT.
OTHERWISE, PLEASE REACH OUT TO YOUR SUPPORT CONTACT.
COMMERCIAL PLUGINS OPERATING WITH REDUCED FUNCTIONALITY
- security
- Cluster health, cluster stats and indices stats operations are blocked
- All data operations (read and write) continue to work
- watcher
- PUT / GET watch APIs are disabled, DELETE watch API continues to work
- Watches execute and write to the history
- The actions of the watches don’t execute
- monitoring
- The agent will stop collecting cluster and indices metrics
- The agent will stop automatically cleaning indices older than [xpack.monitoring.history.duration]
- graph
- Graph explore APIs are disabled
[2022-12-06T10:37:50,168][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:38:50,167][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:39:50,165][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:40:50,166][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:41:50,166][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:42:50,166][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:43:50,165][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:44:50,168][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:45:50,169][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:46:50,168][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:47:37,704][WARN ][o.e.l.LicenseService ] [b1]
LICENSE [EXPIRED] ON [WEDNESDAY, FEBRUARY 21, 2018]. IF YOU HAVE A NEW LICENSE, PLEASE UPDATE IT.
OTHERWISE, PLEASE REACH OUT TO YOUR SUPPORT CONTACT.
COMMERCIAL PLUGINS OPERATING WITH REDUCED FUNCTIONALITY
- security
- Cluster health, cluster stats and indices stats operations are blocked
- All data operations (read and write) continue to work
- watcher
- PUT / GET watch APIs are disabled, DELETE watch API continues to work
- Watches execute and write to the history
- The actions of the watches don’t execute
- monitoring
- The agent will stop collecting cluster and indices metrics
- The agent will stop automatically cleaning indices older than [xpack.monitoring.history.duration]
- graph
- Graph explore APIs are disabled
[2022-12-06T10:47:50,167][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:48:50,167][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:49:50,167][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:50:50,167][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:51:50,168][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:52:50,168][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[2022-12-06T10:53:50,169][INFO ][o.e.i.a.JiebaWordDictionary] Load user dict done. Content: 粉水 100
[hadoop@b1 ~]$
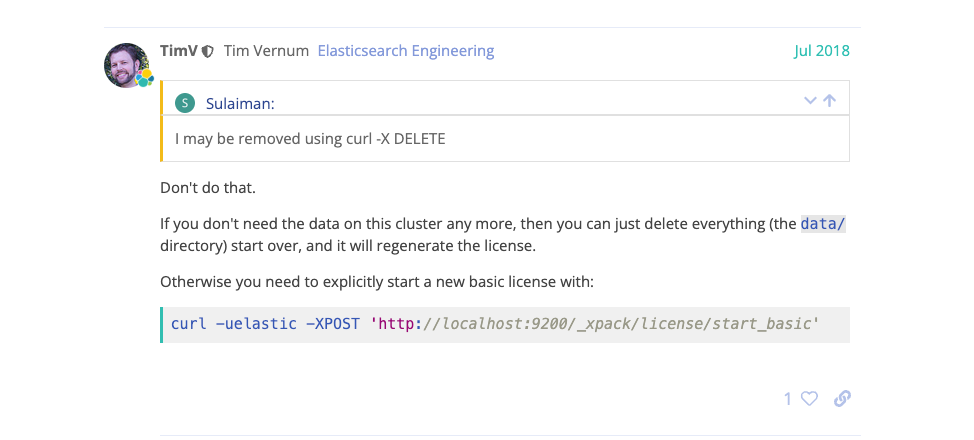
Isn’t this an exception? It prompts that the license has expired, so it can’t join the cluster.
License Expired - #12 by TimV - Elasticsearch - Discuss the Elastic Stack You can take a closer look at the risks of this operation.
This expiration is xpack, it doesn’t matter, every node in our cluster reports this error.
The issue has been resolved; it was related to the temporary and persistent configuration parameters. Thanks to @wakaka for the solution.
After reading for a long time, I realized this discussion is about Elasticsearch.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.