Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiKV cpu资源使用不均,sql执行Coprocessor 累计等待耗时高
[TiDB Usage Environment] Production Environment
[TiDB Version] 6.1.0
[Reproduction Path] Operations performed that led to the issue
[Encountered Issue: Problem Phenomenon and Impact] TiKV resource usage is uneven, SQL execution is slow
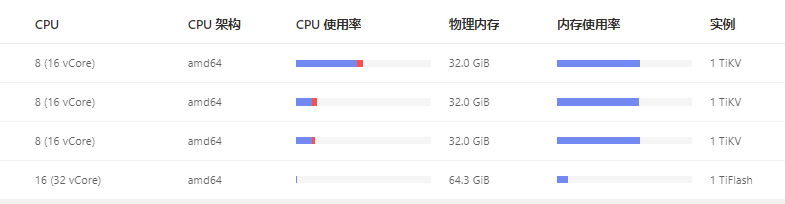
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]
Check if there are hotspot issues with the region.
Most of the reads are from this index. I have already done a split index with 1000, but it has no effect.
-
Use pd-ctl to manually transfer hot regions to nodes with lower load;
-
For hot regions caused by hotspot keys, manually split the hot regions;
-
The above operations may require waiting for scheduling, and scheduling parameters can be modified as needed.
Official documentation: PD Control 使用说明 | PingCAP 文档中心
Check the storage usage; it hasn’t reached the 60% threshold, right?
Based on this diagram, this is clearly a hotspot issue. If it’s a read hotspot, there are quite a few ways to handle it.
-
Try splitting it. If splitting into 1000 parts is not enough, you can try splitting it even further.
-
For read hotspots, if it’s caused by frequent access to a small table, and if the table is smaller than 64MB and not frequently updated, you can set it as a cache table to cache it directly in the memory of the TiDB server.
-
Alternatively, you can trigger the system’s automatic scattering function to balance it by setting set config tikv split.qps-threshold=3000 for QPS exceeding 3k, or set config tikv split.byte-threshold=30 for access traffic exceeding 30MB.
-
Or, if it’s a read hotspot and not a small table, it might be an execution plan issue. Confirm whether the optimizer has chosen the wrong index.
Index hotspot, the table is very large, meaning many SQL queries are using a single index.
ERROR 1105 (HY000): Split index region num exceeded the limit 1000… Unable to split more than 1000, is there any parameter setting for this?
Is the time index they are using reasonable?
If it is not reasonable, you can specify using other indexes and handle it based on the inaccurate execution plan.
If it is reasonable:
- It indicates that it is indeed a hotspot, and you can continuously split and migrate the hotspot regions, splitting them as finely as possible.
- Alternatively, consider the business situation to see if some operations can use other indexes to alleviate the hotspot issue.
- Another option is to scale out the TiKV instances.
- Use NVME SSDs with better performance.
I remember there should be a split-region-max-num parameter that can adjust the maximum number of Regions allowed by the SPLIT TABLE syntax.
You can check the official website for details.
I know why the split had no effect. It was merged again after the split.
Brother, how did you handle it on your end? Please share your experience.