【TiDB Usage Environment】Production Environment
【TiDB Version】v4.0.9
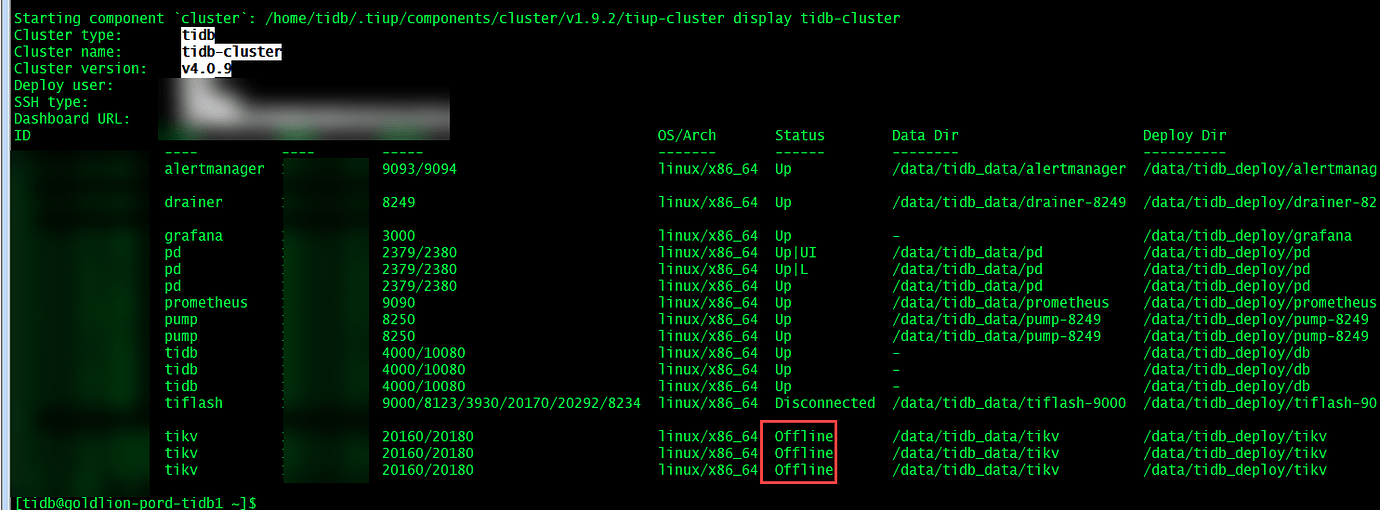
【Encountered Problem】All TiKV nodes in the TiDB cluster are in offline status, what should I do?
【Reproduction Path】Tried restarting the cluster, but the issue was not resolved
【Problem Phenomenon and Impact】
All TiKV nodes in the TiDB cluster are in offline status, how to repair the cluster
Through this attempt, it was also useless. In the end, I solved it by adding other machines to the TiKV cluster to transfer the leader and region away.
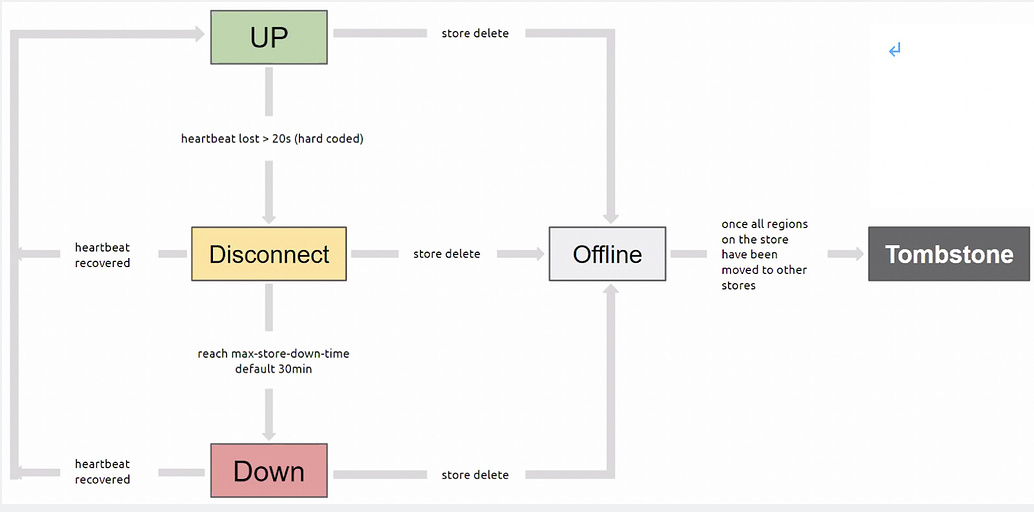
When TiKV is in the offline state, its status is shown as “Offline” in the dashboard. Performing a scale-in on a machine in the offline state will change its status to pending offline. After adding other machines to the TiKV cluster, the machines in the offline state immediately transfer all their regions to the newly added machines. Once the transfer is complete, the machines in the offline state change to the tombstone state. Later, I ran the prune command, and those machines were removed from the cluster.
As for why they were in the offline state, I suspect it might be because I didn’t successfully remove TiFlash. I manually executed a series of commands, here are a few:
tiup ctl:v4.0.9 pd -u http://*.*.*.*:2379 store delete 1
tiup ctl:v4.0.9 pd -u http://*.*.*.*:2379 store delete 4
tiup ctl:v4.0.9 pd -u http://*.*.*.*:2379 store delete 5
I personally think that although those TiKV nodes are in an offline state, they are still providing services because there are no other nodes to take over their regions. Therefore, they remain in the “offline” state.
Of course, in my case above, I successfully backed up the data when TiKV was in the offline state. Actually, restoring the data might be faster. Adding new nodes and letting the system automatically migrate regions takes a lot of time. If you are migrating regions, it is best to adjust the leader-schedule-limit and region-schedule-limit using the pd-ctl command to speed up region migration.
When TiKV is in the offline state, its status is already “offline” when viewed on the dashboard. If you perform a scale-in on a machine in the offline state, it will change to the pending offline state. After adding other machines to the TiKV cluster, the machines in the offline state immediately transfer all their regions to the newly added machines. Once the transfer is complete, the machines in the offline state change to the tombstone state. Later, I ran the prune command, and those machines were removed from the cluster.
As for why they were in the offline state, I guess it might be because I didn’t successfully remove TiFlash. I manually executed a series of commands, here are a few:
tiup ctl:v4.0.9 pd -u http://*.*.*.*:2379 store delete 1
tiup ctl:v4.0.9 pd -u http://*.*.*.*:2379 store delete 4
tiup ctl:v4.0.9 pd -u http://*.*.*.*:2379 store delete 5
Are these deletes for TiKV? The pd store delete command is the offline process. It’s just that you performed this operation on all TiKVs without having extra TiKVs to receive the transferred regions, so the offline state kept appearing but there was still a Leader providing service.