Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 使用TiSpark批量写入,集群不可用
Description: When running batch processing with TiSpark, the cluster experiences high latency during writes, making the cluster unavailable.
Version: TiSpark 2.3.13, TiDB 5.2.4, Spark 2.4.7
Explanation: When loading data with Spark, the latency is slightly high, but it significantly increases during writes.

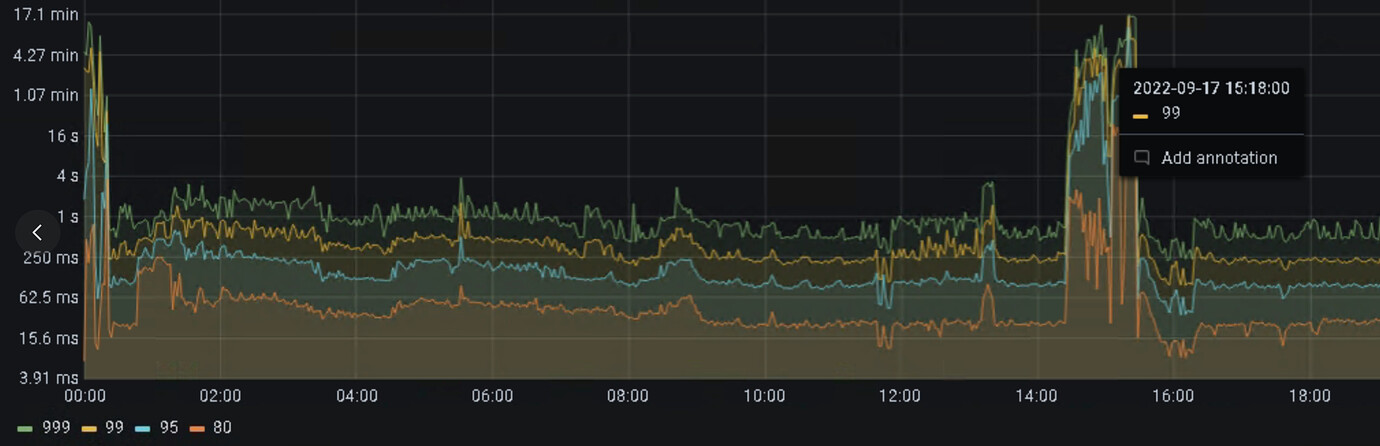
What could be the reason? Is it a parameter configuration issue or a TiSpark version issue?
What is the usage of TiKV’s CPU, memory, and IO?
6 physical machines, each with 160 cores, with high CPU usage on 3 instances.
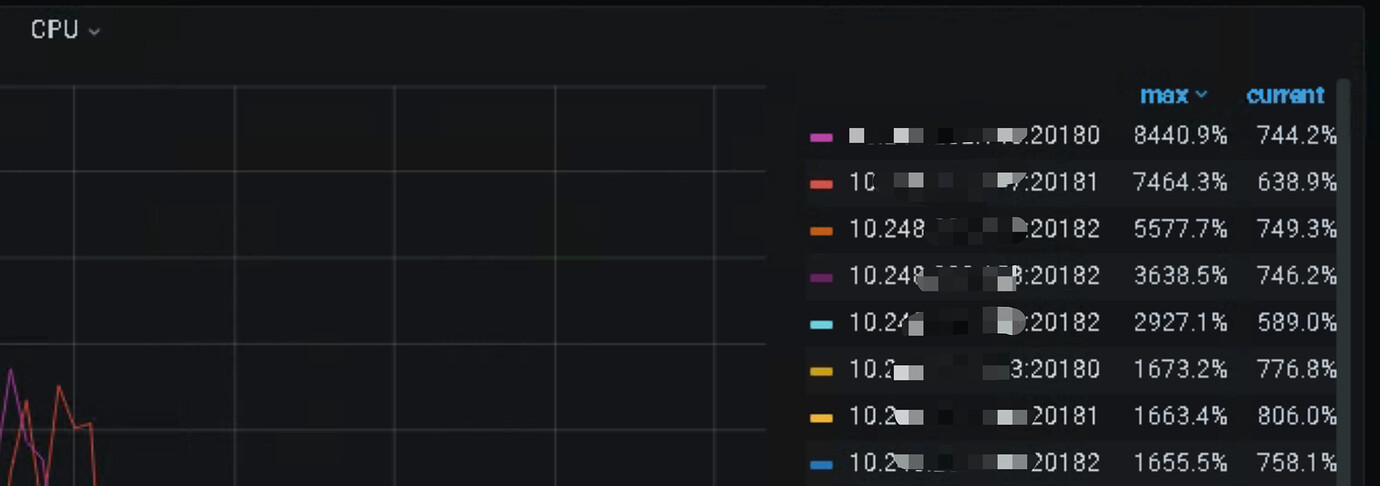
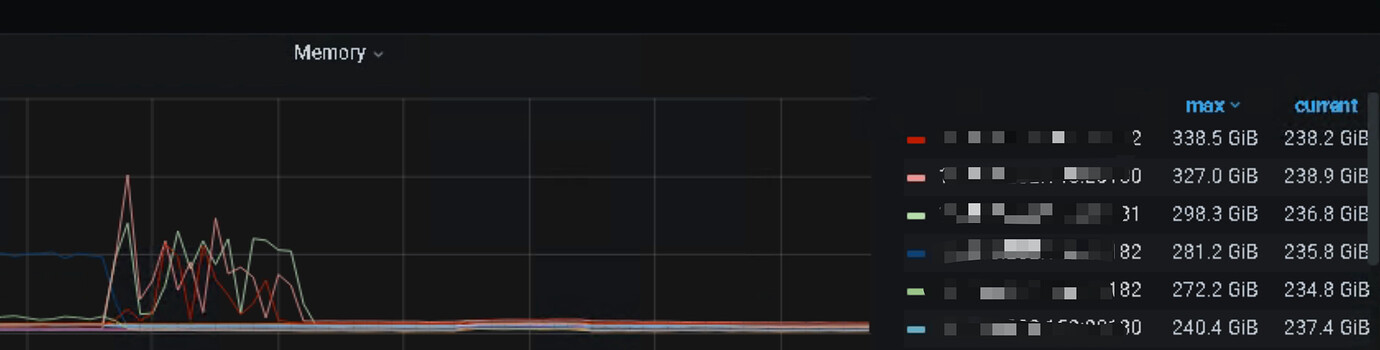
Refer to the slow write, check where exactly it is slow?
It might be a hotspot issue. Trying to use auto_random to disperse the hotspot might help.
There are 3 instances writing more than the others. This table has no primary key, and SHARD_ROW_ID_BITS=6 has been set. Are there any other ways to distribute the load? It seems that when writing to other tables in this way, the cluster latency is significantly high, making the entire cluster unusable, and queries are in a waiting state. Can the resource usage of this kind of TiSpark writing be limited?
As far as I remember, there are no parameters to control concurrency because it writes directly to TiKV. In the case of a small cluster, the interference is relatively large.