Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: V6.5 ticdc 延迟问题
[TiDB Usage Environment] Production Environment
[TiDB Version] V6.5
[Reproduction Path] Operations performed that led to the issue
[Encountered Issue: Problem Phenomenon and Impact]
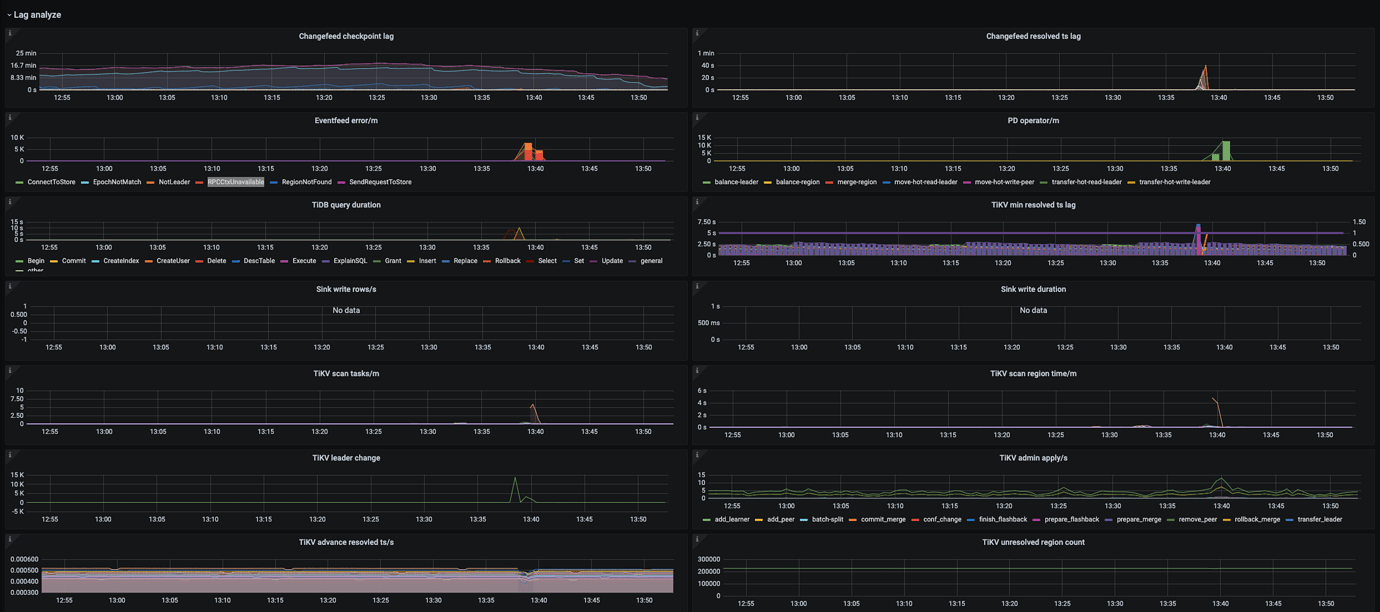
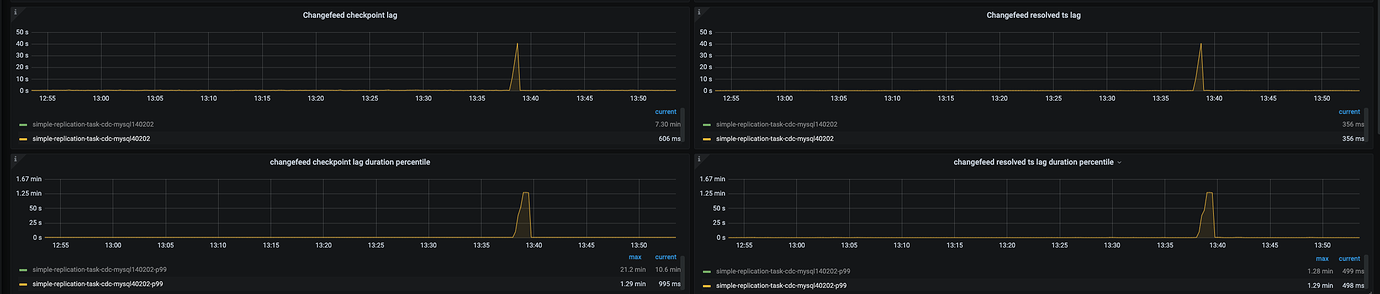
Testing v6.5 version of ticdc for same data center synchronization to downstream MySQL, mostly within seconds, but around 13:39 there was a delay issue of about 40 seconds. Could it be caused by NotLeader and RPCCtxUnavailable and region balance? How to resolve the delay to achieve mostly within seconds?
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]
Check the specific logs to see if there are any records that can verify your hypothesis.
I didn’t see any errors, but when I have 500 transactions and then commit, the latency is somewhat high at 1.4 minutes. How can this be handled? According to the official documentation, transactions are only split if they are larger than 1024.
You can refer to the configuration of CDC transaction splitting here, which is also the current industry practice.
For example, MySQL also splits the files generated by binlog. When Canal simulates a slave to fetch binlog logs, it will also split and read the logs, but it will maintain transactional consistency in processing.
The principle is quite simple: for extremely large transactions, if you read and process them all at once, it requires more memory and network resources. If these conditions are not met, you can only split them and use other methods to maintain transactional consistency.
Which parameter controls the splitting of transactions that exceed a certain size?
You can just refer to the documentation.
It should not be a configuration issue for splitting large transactions. Version 6.5 splits large transactions by default, so no configuration is needed.
Looking at the time and the upstream tikv leader, there are a lot of switches. Why is there no data for the first sink write row in the monitoring?
ticdc does indeed have this issue, and it existed in older versions as well. This sudden delay spike is likely caused by leader switches or region merges in the tidb cluster.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.