Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 命里有时终须有–记与TiDB的一次次擦肩而过
Me
I am a person of considerable weight, and I only buy clothes from Decathlon because their sizes are large. I once admired a tech guru, a very impressive one, who weighed even more than I do, so I felt at ease and thought that perhaps being heavy is a standard for tech experts. I am an old man, and in the community, I can confidently say that my age is among the top. I have been exposed to many things; I have worked with ITIL, written Flex, done platform architecture planning, researched front-end, and even learned and applied SEO on the spot. In recent years, I have been diligently studying data, working on architecture, starting with Hadoop, and constantly tinkering with Spark.
Starting in the Summer of 2019
In 2019, my company assigned me a task to find a database that could handle historical data detail queries, with the requirement to store as much data as possible, support high concurrency, and return results within a user-tolerable time (3 seconds). At that time, a senior colleague in the team compared several databases, including Citus, YugaByteDB, TiDB, etc. TiDB was the first to be tested and also the first to be abandoned. Early versions of TiDB had a deployment check that required disk IOPS to be greater than 10,000 (randread IOPS of tikv_data_dir disk is too low: 8207 < 10000), and if the requirement was not met, it could not be installed. Our old development machines barely had 1K IOPS, so the TiDB test ended without a result. There are similar questions in the forum: https://asktug.com/t/topic/2120. Although Citus, YugaByteDB, and even Cassandra were fully tested and debated, none were put into production for various reasons.
Respond to Every Call, Win Every Battle
In 2021, I did some more research on TiDB. The original goal was to find a cloud-native, Spark-compatible data warehouse view layer database. The expected architecture at that time was as follows:
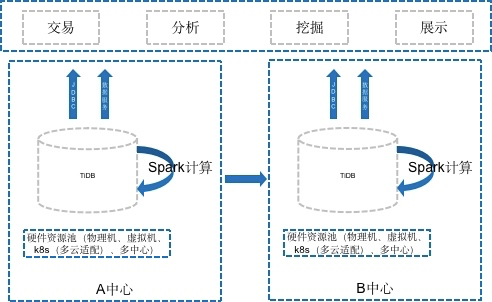
However, that year, we did something unusual and encountered a difficult problem. We used the big data Hadoop stack to calculate bills for customers. Many people around the world do this, but few teams as small and technically weak as ours do. We then encountered issues with inaccurate billing at the beginning and end of the month. The entire synchronization chain was very long, as shown below:

We researched for two weeks, suffering greatly, and I wanted to set up another synchronization chain to compare data and hopefully find the problem. Or, if the new synchronization chain was stable, we could directly trust the new chain’s data. Since TiDB is fully compatible with the MySQL ecosystem and we had Otter in our cluster, I had a bold idea to use TiDB to set up another data synchronization chain and use Spark to sync TiDB data to big data products for computation. The synchronization chain then became like this:
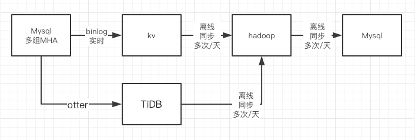
The new synchronization chain took only three days from setting up the production environment to officially processing data. After the new chain went live, we used a complementary approach with both chains to calculate bills, and there were no more data issues. After two weeks of tracking, we gradually identified problems in the previous environment and fixed them. The TiDB synchronization chain then completed its mission.
Details: https://tidb.net/blog/55a8baf9
The Closest to Production
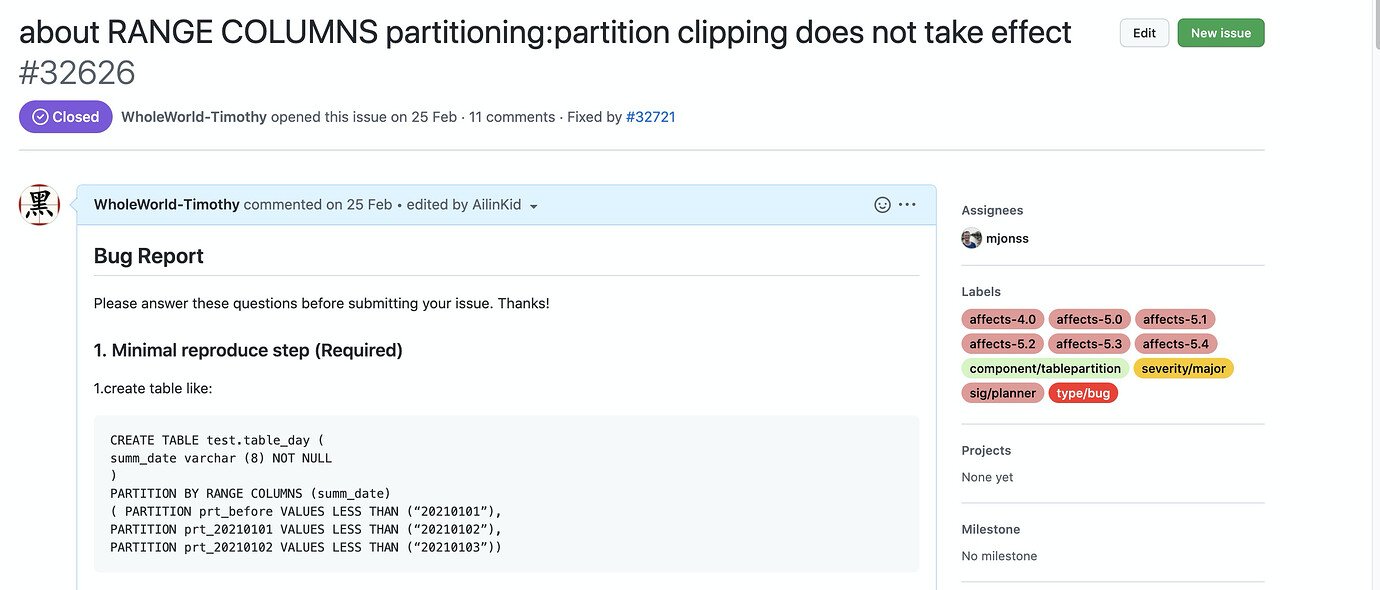
In 2022, I gradually became involved in the community. I also conducted some training within the company and set up a test environment. Due to my layout, another team thought of TiDB when they needed to solve the underlying query issues of the Saiku product, so they did some testing. From the results, TiDB was more suitable for Saiku’s query methods than other databases in the environment. We then planned to go live with TiDB in production to solve many issues in our production environment, not just for Saiku but also for many areas requiring a distributed relational database. However, due to external factors, we ultimately deployed Doris, as Saiku performed better on Doris in tests. During this process, we discovered some issues and raised our first issue on TiDB, which was fixed in a new version:
https://github.com/pingcap/tidb/issues/32626
Details: https://tidb.net/blog/de9bf174
Never Stop Learning and Tinkering
As I get older, I increasingly realize the importance of knowledge reserves. A crucial way to acquire knowledge is to deeply participate in the community.
So, I:

So, I:

So, I:

And the following, those who understand will understand, hhhhhhhhhh:

Finally, thank you to your company for helping me fulfill my dream of a distributed database.