Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiDB的pd服务一直跑不起来,导致tidb和tikv的pod出现不了怎么办?
【TiDB Usage Environment】Production Environment / Testing / PoC
【TiDB Version】
【Reproduction Path】What operations were performed when the issue occurred
【Encountered Issue: Issue Symptoms and Impact】
【Resource Configuration】
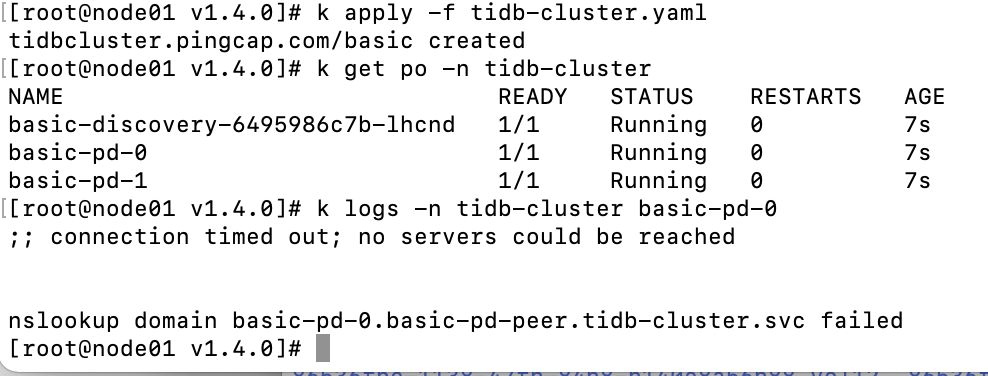
【Attachments: Screenshots / Logs / Monitoring】
The log error of tidb-controller-manager-65b7c5756c-bjkqq is as follows:
I0325 12:35:02.594685 1 tidbcluster_control.go:71] TidbCluster: [tidb-cluster/basic] updated successfully
I0325 12:35:02.594735 1 tidb_cluster_controller.go:131] TidbCluster: tidb-cluster/basic, still need sync: TidbCluster: [tidb-cluster/basic], waiting for PD cluster running, requeuing
E0325 12:35:07.708892 1 pd_member_manager.go:205] failed to sync TidbCluster: [tidb-cluster/basic]'s status, error: Get "http://basic-pd.tidb-cluster:2379/pd/api/v1/health": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
I0325 12:35:07.736119 1 tidb_cluster_controller.go:131] TidbCluster: tidb-cluster/basic, still need sync: TidbCluster: [tidb-cluster/basic], waiting for PD cluster running, requeuing
E0325 12:35:12.877920 1 pd_member_manager.go:205] failed to sync TidbCluster: [tidb-cluster/basic]'s status, error: Get "http://basic-pd.tidb-cluster:2379/pd/api/v1/health": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
I0325 12:35:12.921957 1 tidbcluster_control.go:71] TidbCluster: [tidb-cluster/basic] updated successfully
I0325 12:35:12.922015 1 tidb_cluster_controller.go:131] TidbCluster: tidb-cluster/basic, still need sync: TidbCluster: [tidb-cluster/basic], waiting for PD cluster running, requeuing
E0325 12:35:18.047214 1 pd_member_manager.go:205] failed to sync TidbCluster: [tidb-cluster/basic]'s status, error: Get "http://basic-pd.tidb-cluster:2379/pd/api/v1/health": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
I0325 12:35:18.069235 1 tidb_cluster_controller.go:131] TidbCluster: tidb-cluster/basic, still need sync: TidbCluster: [tidb-cluster/basic], waiting for PD cluster running, requeuing
E0325 12:35:41.882132 1 pd_member_manager.go:205] failed to sync TidbCluster: [tidb-cluster/basic]'s status, error: Get "http://basic-pd.tidb-cluster:2379/pd/api/v1/health": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
I0325 12:35:41.915237 1 tidb_cluster_controller.go:131] TidbCluster: tidb-cluster/basic, still need sync: TidbCluster: [tidb-cluster/basic], waiting for PD cluster running, requeuing
[root@node01 v1.4.0]# k logs -n tidb-admin tidb-controller-manager-65b7c5756c-bjkqq
I read that post, and his final solution was to reinstall the network plugin because his two network plugins were always pending. However, my network plugin is running normally:
[root@node01 kube-prometheus]# k get po -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-66686fdb54-2ccg6 1/1 Running 2 (6h55m ago) 6h55m
calico-node-4dfhd 1/1 Running 0 6h55m
calico-node-6v8wm 1/1 Running 0 6h55m
calico-node-rw54s 1/1 Running 3 (14m ago) 6h47m
calico-typha-67c6dc57d6-ctph8 1/1 Running 2 (14m ago) 3h2m
calico-typha-67c6dc57d6-f4q6k 1/1 Running 0 3h11m
calico-typha-67c6dc57d6-j4mmv 1/1 Running 0 6h55m
coredns-7d89d9b6b8-7w9t9 1/1 Running 0 80m
coredns-7d89d9b6b8-pdz27 1/1 Running 0 81m
etcd-node01 1/1 Running 0 6h56m
etcd-node02 1/1 Running 0 6h57m
But my port 2379 is occupied by the k8s etcd service. Could this be the reason? If so, how do I configure the PD port? I’ve searched for a long time but couldn’t find it.
The default component pod should use the internal IP and not conflict with the node port, so you can only adjust the CNI. The Operator currently does not support adjusting component ports, as they are hardcoded in the code: Code search results · GitHub
Could you please provide some guidance on how to adjust the CNI?
Installing Addons | Kubernetes Different CNIs are not quite the same. You’d better look for the corresponding CNI documentation or technical support to solve the k8s network issues.