Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiDB表结构设计时什么场景该设置随机主键,什么场景该使用业务主键,什么场景该使用自增主键?
I’ve always had a question about the table structure design in TiDB, specifically regarding the setting of primary keys. In what scenarios should a random primary key be set, in what scenarios should a business primary key be used, and in what scenarios should an auto-increment primary key be used?
For example:
- After setting a random primary key, it is more friendly when importing large amounts of data, but when deleting or updating in batches based on the primary key, it is found that because of the random primary key setting, it is still easy to scan the entire table, leading to OOM (Out of Memory).
- After setting an auto-increment primary key, it is easy to encounter hotspot issues when importing large amounts of data.
- Setting a business primary key sometimes also leads to hotspot issues because some business primary keys themselves have continuity, and _tidb_rowid itself is continuous.
Of course, some people say that for primary key designs with hotspot issues, scattering and presetting Regions can be done, but after scattering and presetting Regions, it is found that in some query stress tests, the query efficiency has a noticeable decline.
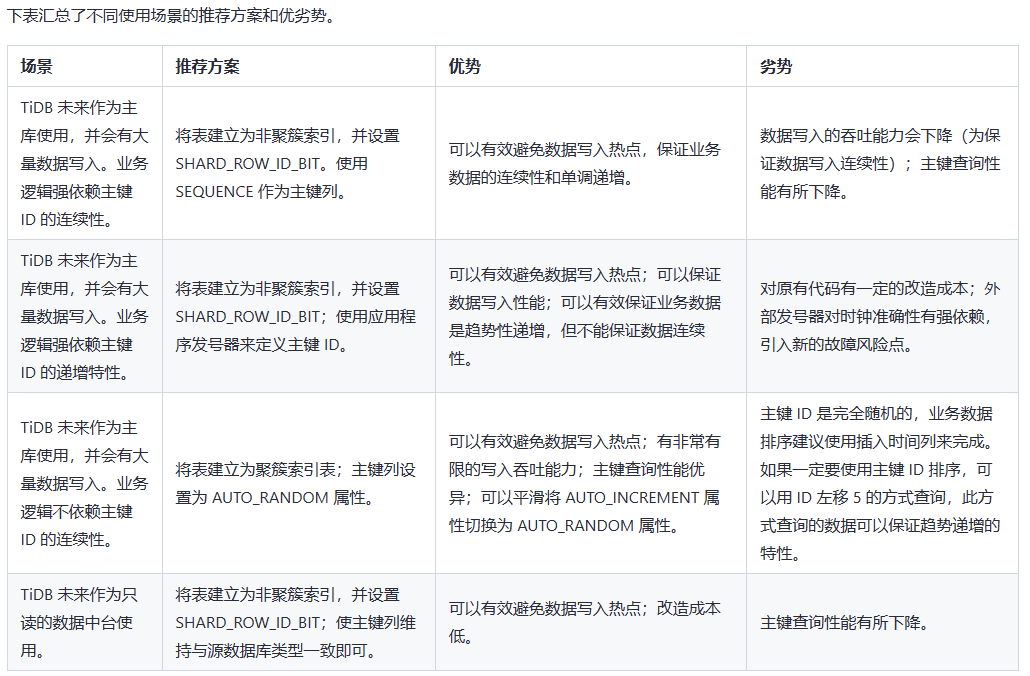
Using AUTO_RANDOM to handle auto-increment primary key hotspot tables is suitable for replacing auto-increment primary keys and solving the write hotspot issue caused by auto-increment primary keys. After using this feature, TiDB will generate randomly distributed primary keys that do not repeat before the space is exhausted, achieving dispersed writes and mitigating write hotspots.
TiDB Hotspot Issue Handling | PingCAP Documentation Center
According to my tests, the write performance of clustered tables is significantly faster than non-clustered tables, regardless of whether the primary key is numeric or not. Each additional secondary index will greatly reduce the write performance.
Clustered table regions can be scattered using the Split Region method, refer to
Split Region Documentation | PingCAP Documentation Center
There is a detailed explanation of this in the 301 video.
In the best case scenario, use random primary keys or non-clustered tables with shard_row_id_bit. This significantly addresses hotspot issues. Whether it’s a business primary key or an auto-increment primary key, it generally leads to hotspot problems.
It is certain that random primary keys help to disperse hotspots, but if random primary keys are set and the table needs to be batch deleted, it is easy to perform a full table scan if the batch deletion is based on random primary keys.
Clustered table access performance is also faster than non-clustered tables because it can reduce one table lookup; adding secondary indexes means more data is written, so writes will be slower.
If you need to batch delete with random primary keys, it can easily cause a full table scan. How can this be avoided?
The primary key itself does not have any business significance; it only needs to be unique and non-repetitive. If there are business requirements, you can add another field. You don’t need to consider your third question; you can consider using random numbers, and when deleting, you can use rownum.
You must be referring to a very old version, right? After version 6.5, clustered tables write much faster than non-clustered tables. The performance of sequences is very poor, but using auto-increment with cache=1 has been optimized and is now much faster.
It is generally recommended to record the keys first and then delete them by key when performing batch deletions. The more dispersed your keys are, the faster the deletion should be.
Distributed databases do not recommend using auto-increment primary keys. For scenarios that require auto-increment primary keys, it is better to use MySQL.
I personally think that the business primary key is not suitable.
To basically avoid hotspots:
For clustered index tables, use AUTO_RANDOM to avoid hotspots;
Since AUTO_RANDOM does not support non-clustered index tables, use SHARD_ROW_ID_BITS to avoid hotspots in the case of non-clustered index tables;
Other detailed issues need to be analyzed specifically.
When deleting in batches by random primary key, some keys are too scattered, which leads to scanning more regions and ultimately results in a full table scan.
But isn’t your random primary key just table_id plus primary key? Point queries or range queries should be faster than other index back table methods, right… It also won’t return all regions…
Personally, I feel it is still to solve the hotspot issue.