Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 在做bad-ssts的时候发现文件不存在,没有给出相关提示,需如何操作才能恢复呢?
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version] 6.1
[Encountered Problem: Problem Phenomenon and Impact]
Querying the table often results in the error “ERROR 9005 (HY000): Region is unavailable”. When performing bad-ssts, it was found that the file does not exist and no relevant prompt was given. How should I proceed to fix this?
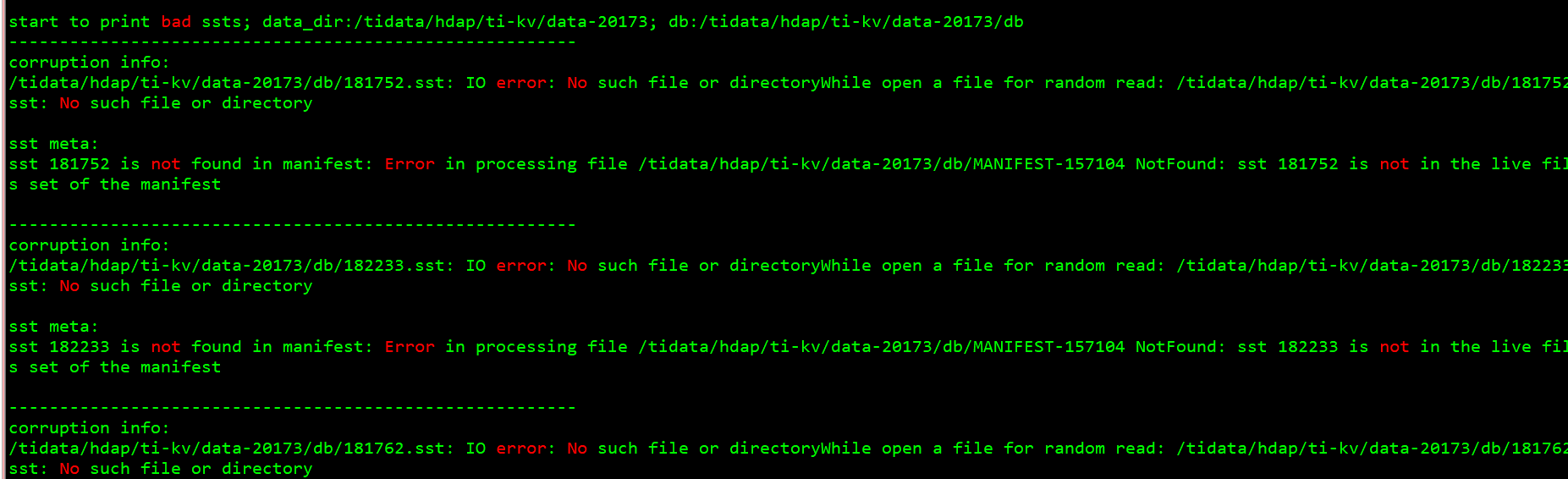
start to print bad ssts; data_dir:/tidata/hdap/ti-kv/data-20173; db:/tidata/hdap/ti-kv/data-20173/db
corruption info:
/tidata/hdap/ti-kv/data-20173/db/181752.sst: IO error: No such file or directory While opening a file for random read: /tidata/hdap/ti-kv/data-20173/db/181752.sst: No such file or directory
sst meta:
sst 181752 is not found in manifest: Error in processing file /tidata/hdap/ti-kv/data-20173/db/MANIFEST-157104 NotFound: sst 181752 is not in the live files set of the manifest
Scale down and then scale up again, there’s no need to mess around.
I have already scaled up and down once, but it’s still like this 
How did you do it? This is a big move.
First remove the newly expanded nodes, and then re-expand.
Did expanding the capacity make the file disappear? 
After an expansion, files are still missing? Should we check if there are any issues with the file system or the disk?
You can check out this column
Where did this error message come from? Check the region status:
pd-ctl region xxxx
tikv-ctl --host xxx:20160 raft region -r XXXX
This error occurs when querying a table or performing a count(), previously it reported “Region is unavailable”, now it reports a long string like this:
/ SQL Error (1105): no available peers, region: {id:733765 start_key:“t\200\000\000\000\000\000\005j_i\200\000\000\000\000\000\000\001\003\200\000\000\000\004BD2” end_key:“t\200\000\000\000\000\000\005j_i\200\000\000\000\000\000\000\001\003\200\000\000\000\004M_\232” region_epoch:<conf_ver:557 version:7266 > peers:<id:733768 store_id:18 > peers:<id:3086601 store_id:8 > peers:<id:14470098 store_id:7 > } */
Now I am expanding and shrinking the problematic nodes one by one, and then trying to check again.
Generally, this error indicates a disk issue. You can try to repair it. If it can’t be repaired, locate the problematic replica in the specific region and remove all KVs from that replica.