Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tidb集群中的某张表,主库集群某一条记录进行update更新时,从库1可以正常更新,从库2没有对此条记录进行正常更新
【TiDB Usage Environment】Production Environment
【TiDB Version】v6.5.0
【Reproduction Path】In a certain table of the TiDB cluster, when updating a record in the primary cluster, the update is normal in Replica 1, but not in Replica 2.
【Encountered Problem: Phenomenon and Impact】In a certain table of the TiDB cluster, when updating a record in the primary cluster, the update is normal in Replica 1, but not in Replica 2.
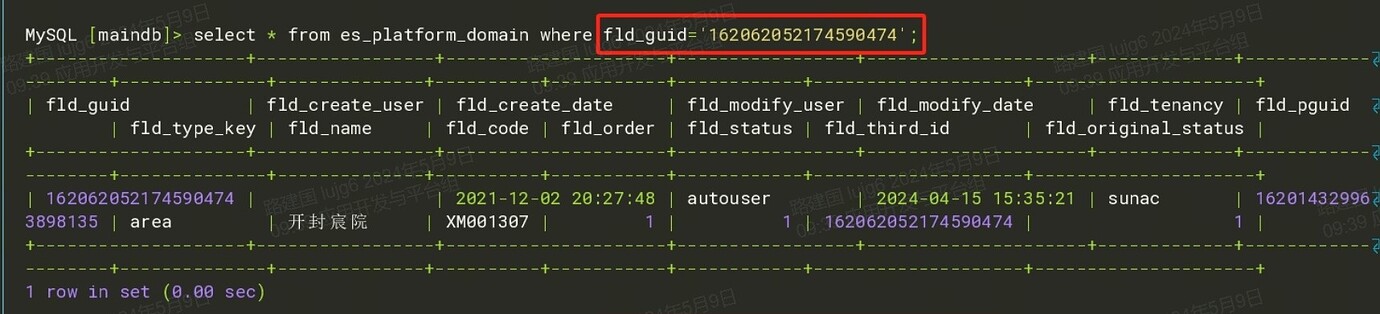
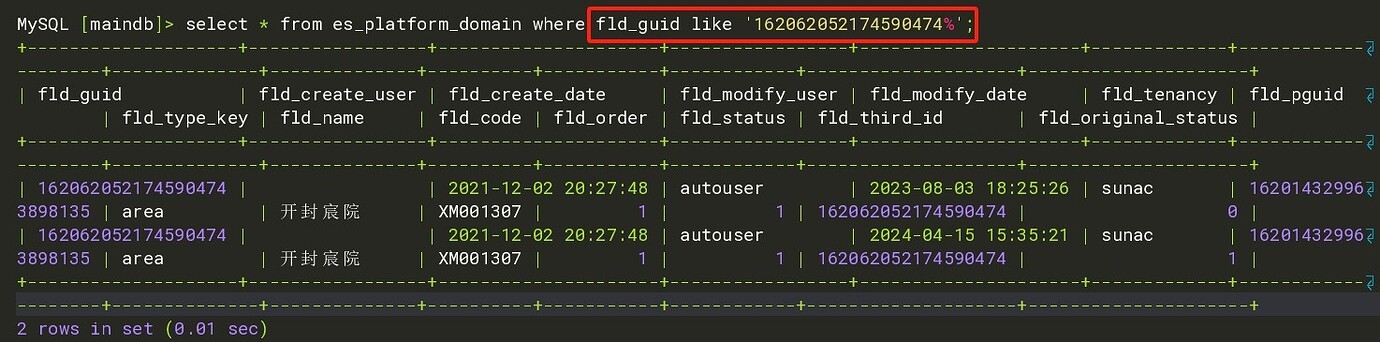
- Currently, the method used is to re-dump the data of this table from the primary cluster and then import it into Replica 2, and recreate the CDC task for synchronization.
- Several other business tables related to this table also have this issue. Is there a better way to directly query this table in Replica 2 for records with the same primary key?
【Resource Configuration】Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
【Attachments: Screenshots/Logs/Monitoring】