Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiFlash存算分离架构下在增加TiFlash副本时候,为什么Read比Write大很多
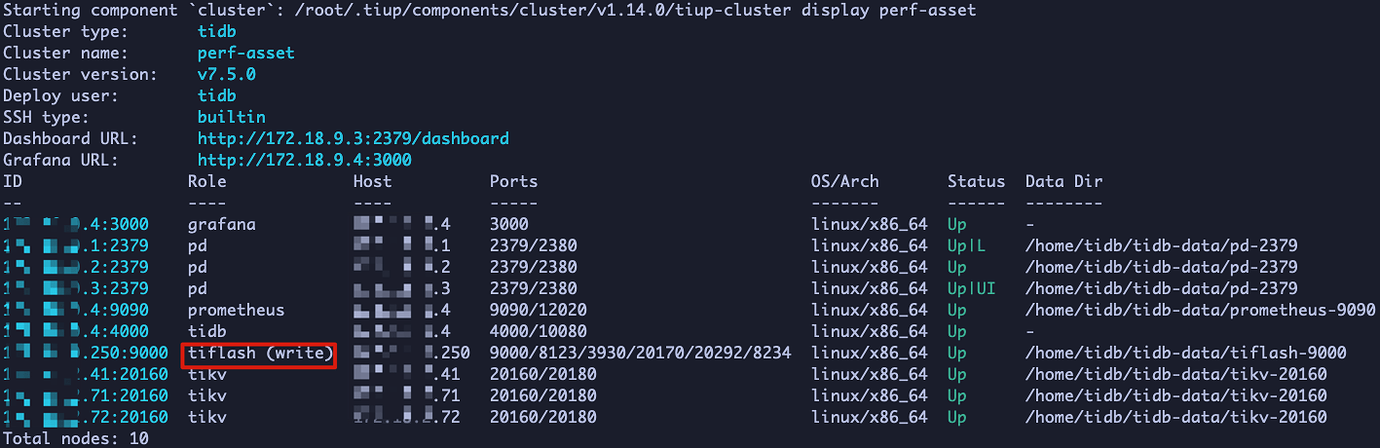
Cluster configuration has only one tiflash write_node node and no compute nodes:
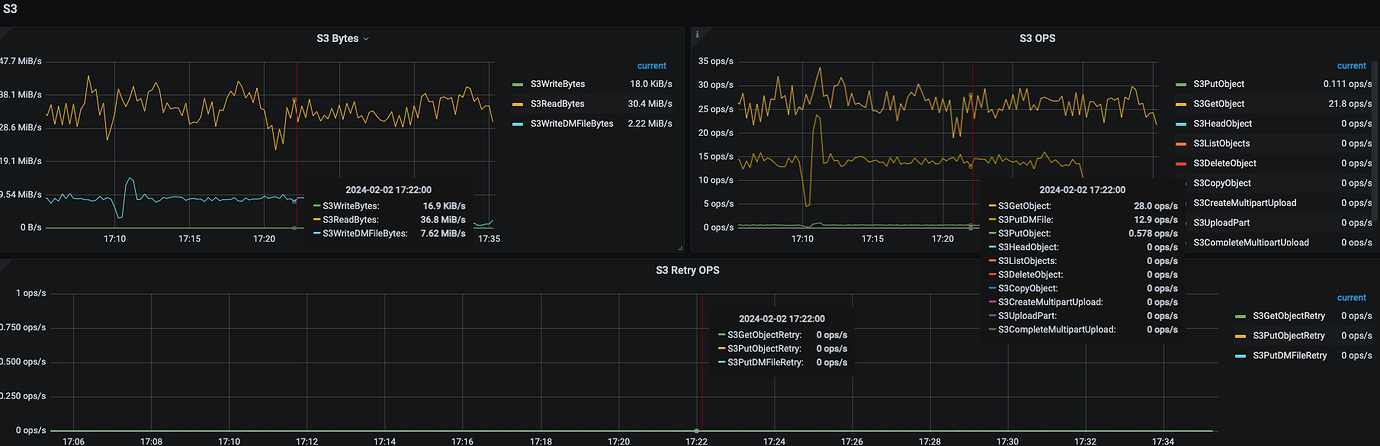
Looking at the monitoring, after setting tiflash replica 1, the Read operations on OSS by tiflash are significantly more than the Write operations. What is the reason for this?
It might be due to some management actions. Let’s check again after some time. 
TiFlash replicas are synchronizing data.
TiFlash is originally designed for MPP, which is meant to handle a large number of reads.
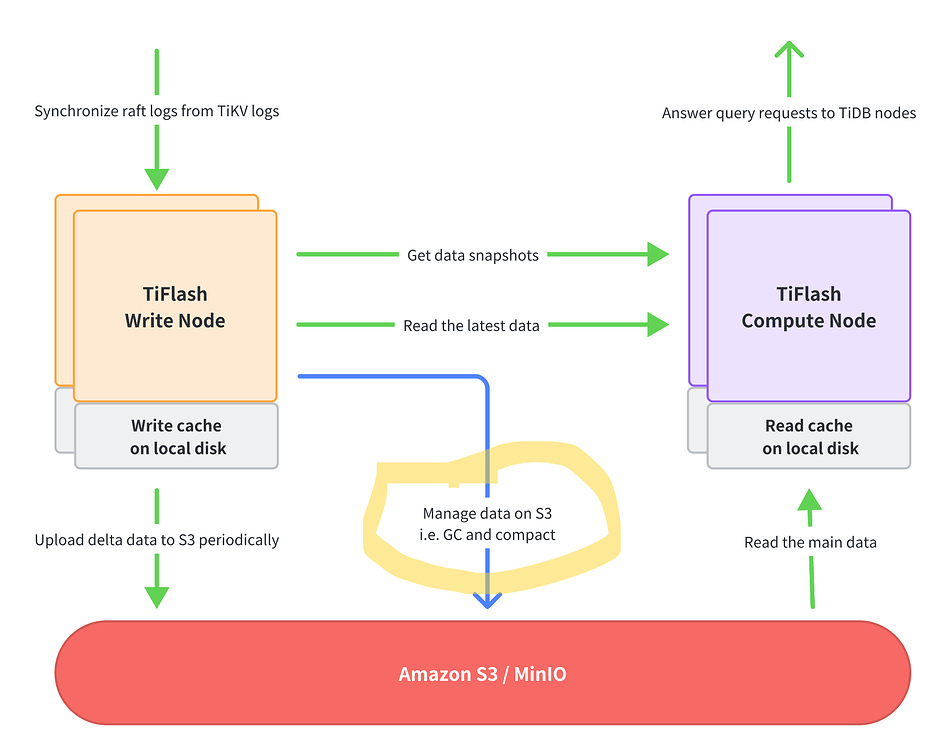
After carefully reading the documentation, I now roughly understand that the so-called write_node’s local data is really just a cache. The amount of data is very, very small, merely serving as a write cache, and it will be deleted locally after successfully writing to S3.
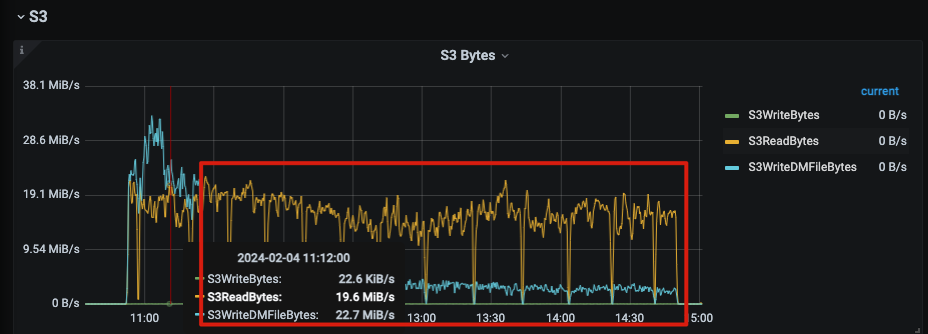
By analyzing the monitoring data from that period, it can also be found that even during the migration, the local data of the write_node was always only about 4 MB. The content on S3 was 96 GB after the initial upload, but after a period of stabilization, it was only 55 GB, and TiFlash no longer performed GET operations on S3. (This cluster is a test cluster with no read/write requests, only static data)
From this, it can be seen that the current TiFlash on S3 architecture uses S3 as a regular disk. There are as many subdirectories on S3 as there are write_node nodes, with each directory corresponding to a write_node node.
Daily operations such as Merge/Split/GC/compact all require direct reading and writing of data in S3.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.