Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 为什么cop_task的执行时间比该算子(甚至其父算子)的总执行时间要长?
To improve efficiency, please provide the following information. A clear problem description can help solve the issue faster:
[TiDB Usage Environment] Academic Research
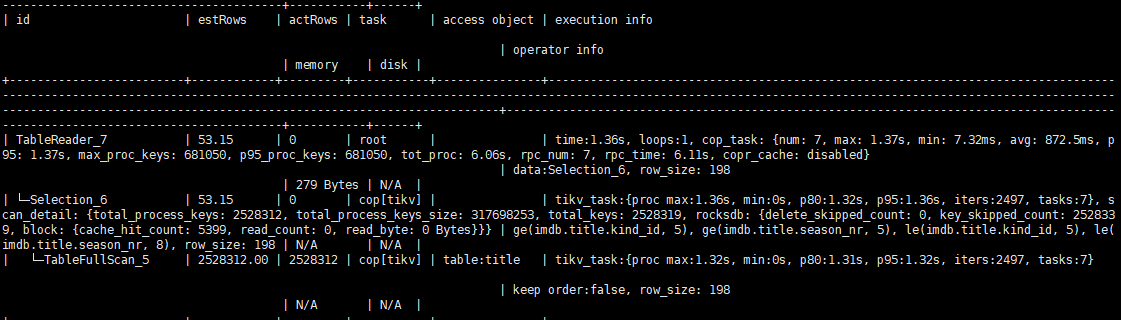
[Overview] Using EXPLAIN ANALYZE to observe TiDB’s execution plan, I found that the tot_proc time of cop_task is shorter than the execution time of the operator (or even its parent operator), which is somewhat counterintuitive. As shown in the figure below, the execution time of the Table_Reader operator is 1.56 seconds, while the tot_proc of cop_task is as high as 6.06 seconds. Is this because multiple TiKV instances are processing simultaneously?
In the figure below, the Index_Reader_11 and HashAgg_10 operators also have the phenomenon where the cop_task execution time (452ms) is longer than the execution time of the node and its parent node (275ms).
[Background] explain analyze
[TiDB Version] 5.3
[Application Software and Version]
[Attachments] Relevant logs and configuration information
- TiUP Cluster Display Information: 3 TiKV instances
If the question is related to performance optimization or troubleshooting, please download the script and run it. Please select all and copy-paste the terminal output.
In the statistics of cop tasks, there are cumulative values. TiDB sends dist-scan-concurrency cop tasks to TiKV for parallel execution at once. According to the second example, TiDB issues 2 cop tasks, and TiKV executes them as 2 tikv_tasks: 272ms + 180ms, which exactly matches the tot_proc time of the index_reader. Since there are 2 tikv_tasks, the time for the index_reader operator is the maximum tikv_task return time plus some additional processing time (which should be tot_wait).
Got it, so may I ask if these two cop_tasks are executed on two different TiKV nodes or in parallel on the same node?
Look at the region distribution, one region corresponds to one cop task.
Can we specify to make cop_task serial or execute in order?
You can set the parameters tidb_distsql_scan_concurrency, tidb_index_lookup_concurrency, tidb_index_lookup_join_concurrency, and tidb_executor_concurrency all to 1.
After setting these parameters to 1, can I still obtain the execution time of a single operator? Because it is serial, the time for the index_reader operator is no longer the maximum tikv_task return time plus some other processing time, but the sum of each task, and currently, there are only max, min, p95, and p80 statistical values.
You can trace and check the access time of each region.
Got it~ So you can’t see it from the execution information of explain analyze, right?
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.