Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 为什么走了tiflash 查询反而更慢了
Why is the query speed slower when using TiFlash?
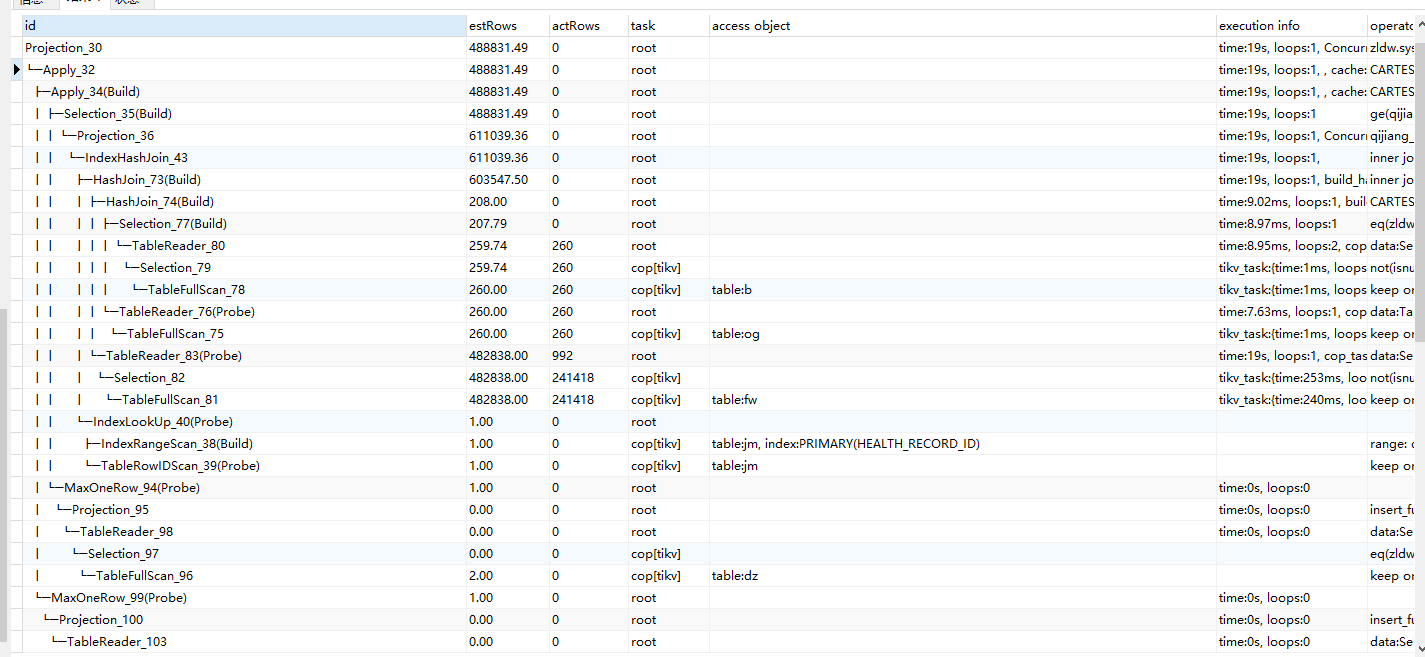
This is the initial execution plan without TiFlash:
This is the execution time of the SQL, around 20 seconds:
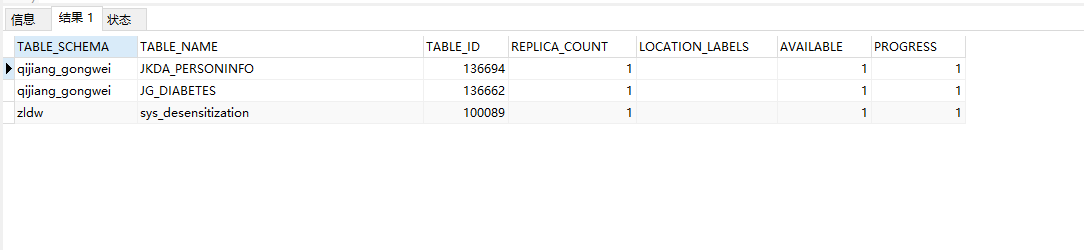
Setting the TiFlash replica for the table:
ALTER TABLE zldw.sys_desensitization SET TIFLASH REPLICA 1;
ALTER TABLE qijiang_gongwei.JG_DIABETES SET TIFLASH REPLICA 1;
ALTER TABLE qijiang_gongwei.JKDA_PERSONINFO SET TIFLASH REPLICA 1;
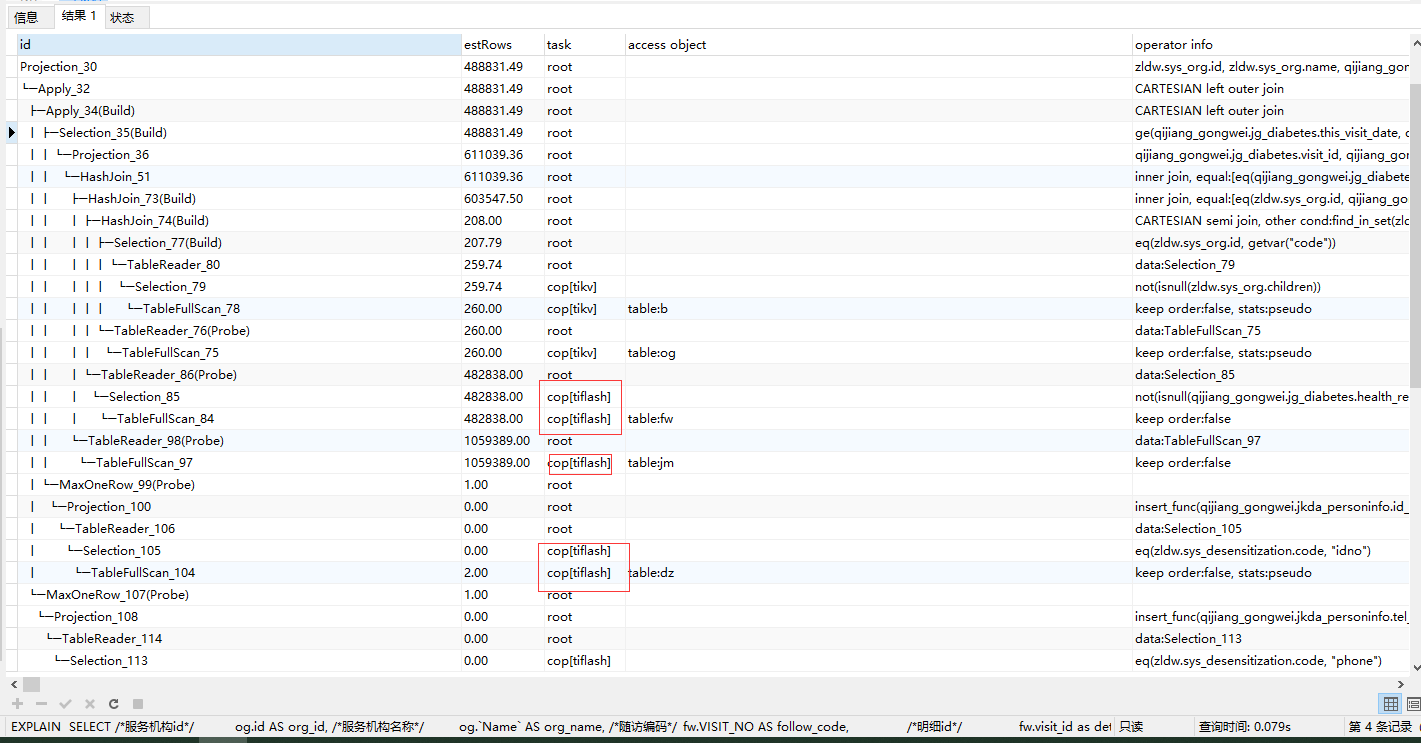
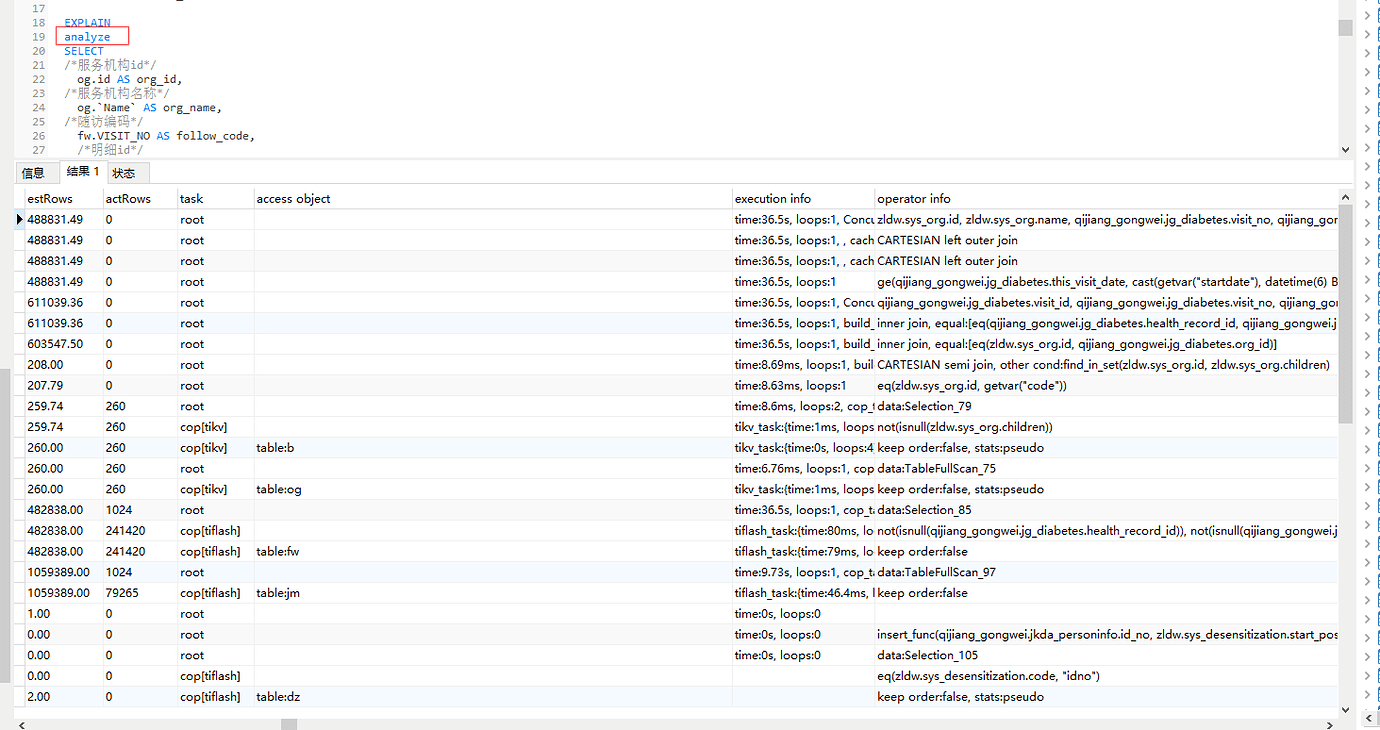
This is the execution plan using TiFlash:
This is the query execution time using TiFlash, 37 seconds, which is 17 seconds more than without TiFlash:
It doesn’t necessarily mean that using TiFlash will be faster than TiKV; it just gives the CBO optimizer one more option. Also, I didn’t see any MPP operators in your execution plan.
It might be due to inaccurate statistics causing the optimizer to make incorrect choices, resulting in some operators not being pushed down, which slows things down. I suggest you analyze the relevant tables and try again.
Additionally, which version of TiFlash are you using? Is there only one node?
I used the tiup command to scale out the 3 nodes directly, so they should be consistent with the database version.
I have tried the “analyze” command.
Aren’t all these operators able to use TiFlash?
The relationship between a 1.5 million row table and whether it uses an index.
From the execution plan, it shows a mix of TiKV and TiFlash usage without using MPP computation, as there are no ExchangeSender and ExchangeReceiver operators. Since TiFlash doesn’t have indexes, mixing them means a full column scan.
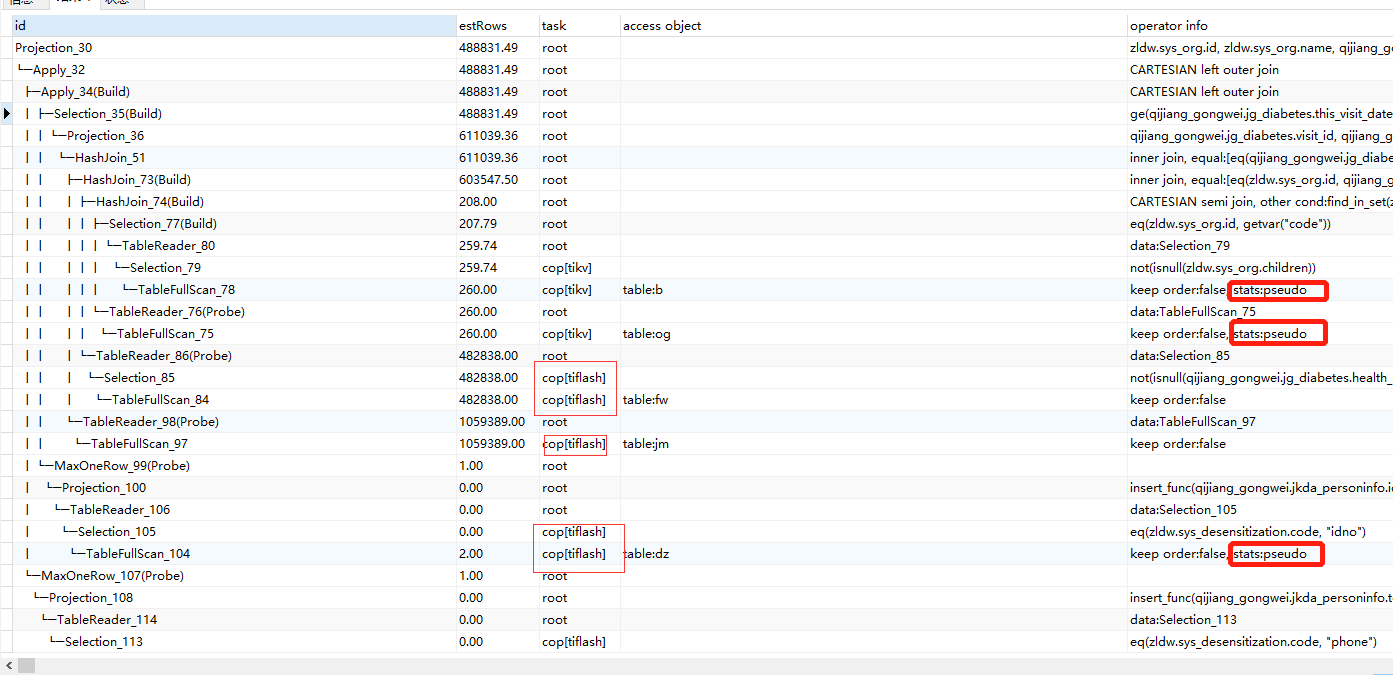
Why does the execution plan still show that your statistics are outdated? 
I didn’t see actrows, so I can’t determine whether these tables will affect the optimizer’s choice.
How do you create an index on TiFlash?
I am talking about ANALYZE TABLE table_name. It recollects the table’s statistics.
analyze TABLE qijiang_gongwei.JG_DIABETES;
analyze TABLE qijiang_gongwei.JKDA_PERSONINFO;
It worked, but the query speed is still the same slow.
TiFlash does not support indexes.
Not supporting indexes should not be faster than TiKV.
So what are its advantages? When the data volume is large, you still need indexes, right?
The advantage is supporting MPP computation or wide table scenarios. For example, if your table has 200 columns and you only need to aggregate a few specific columns, the advantage of column storage becomes apparent.
Please share the column on the right side of the execution plan that includes the time.
If you have 3 nodes, try changing the replica count to 2 first.