Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: BR恢复时为什么同一个文件会被多个tikv节点读取?是因为多副本的原因吗?
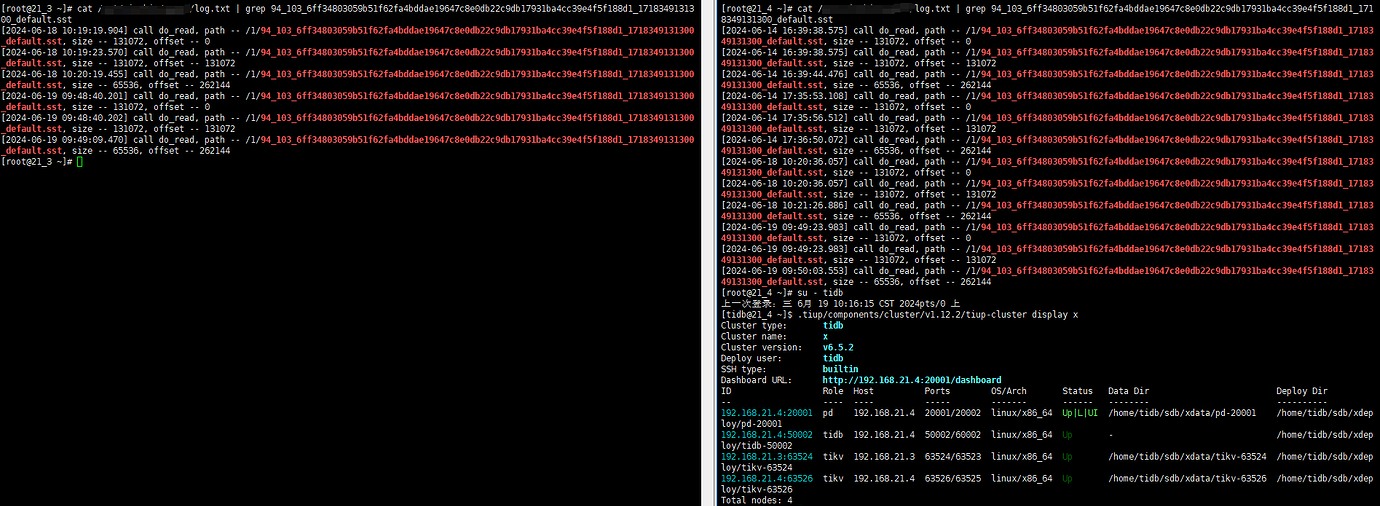
As shown in the figure below, the file 94_103_6ff34803059b51f62fa4bddae19647c8e0db22c9db17931ba4cc39e4f5f188d1_1718349131300_default.sst has read requests on both nodes 21.3 and 21.4:
Based on your configuration, if the backup data is placed in a shared folder, multiple replicas will definitely be read by multiple nodes.
Because the data in one of your files will be in multiple regions, and multiple regions may exist on each node.
It’s not a shared storage issue, right? This way, the backup will be distributed across various servers. It’s best to put them together during recovery.
Automatically scatter during recovery.
The data must be stored together, otherwise BR will report an error and exit if it can’t find the desired file. In this case, the recovery was successful.
What does “automatic sharding” mean?
Is it possible for the same piece of data in a file to be in multiple regions? According to the logs, two nodes both read 131072 bytes of data from the offset 0 of the file.
According to the official documentation, different regions should contain different data.
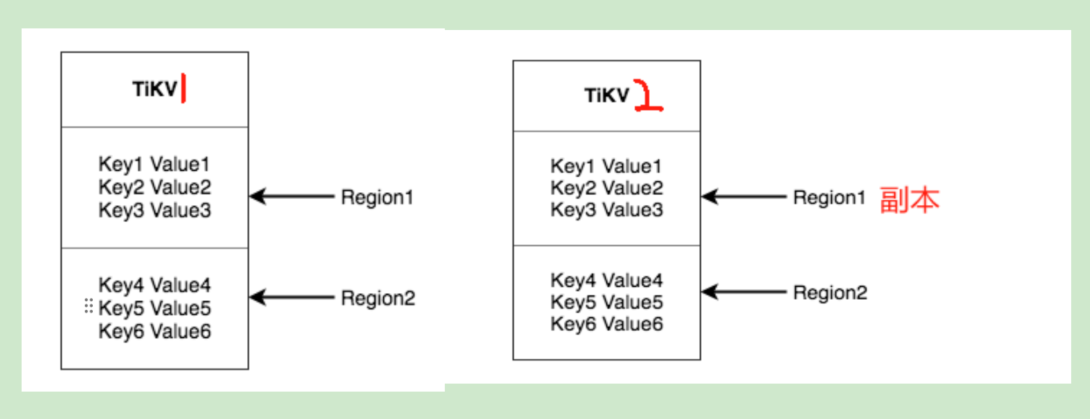
Can I understand your meaning as there is a replica of region1 from node1 on node2, so the same piece of data in the file will be written to both region1 and its replica during recovery, similar to the diagram below:
A single SST contains multiple regions, and these regions are automatically scattered to different stores.
So both nodes here have read the same piece of data (reading 131072 from the offset 0 of the file):
Can it be understood that the same region within a single SST has been scattered across different stores?
The region is the smallest unit. An SST contains multiple regions. You can place regions 1/4/7 from the SST into store1, 2/5/8 into store2, and 3/6/9 into store3.
According to this, this phenomenon is unreasonable. How should we understand different nodes reading the same block of data within the same file?
I understand that reading is to find data suitable for this node.