Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: TiDB性能为什么这么差(其实是报告解读问题)
The official sysbench read-write results seem to be significantly off. Was there a mistake with the data?
Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: TiDB性能为什么这么差(其实是报告解读问题)
The official sysbench read-write results seem to be significantly off. Was there a mistake with the data?
You wouldn’t be like me, using three lousy machines with mechanical disks for mixed deployment, right? That might be the only way…
Are the hardware configurations for local testing and official testing the same?
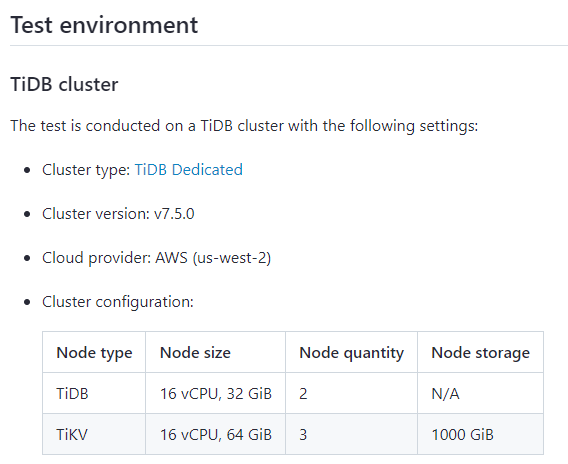
Also, configuration adjustments
Are you here to cause trouble? You didn’t even provide the configuration.
The official test results are based on such a cloud configuration, which is the expected result. Note that this is the TPS mixed with query and write operations, which is the number of transactions executed per second.
If you only look at point_select under this resource configuration, it can reach hundreds of thousands, and pure write can also reach tens of thousands.
If you test with a higher resource configuration, the values can also be improved.
Distributed systems have high requirements for the network.
The title is a bit exaggerated. With the same configuration on a single machine, it might be slower than MySQL. However, with standard configuration and large data volumes, it will definitely perform better.
It seems that everyone has misunderstood.
The original poster did not test it themselves, they just think that the oltp_read_write results are much lower than oltp_point_select? It is recommended to analyze the lua scripts corresponding to different test modes.
It depends on the number of your machines, their corresponding hardware configurations, and the topology file configuration information.
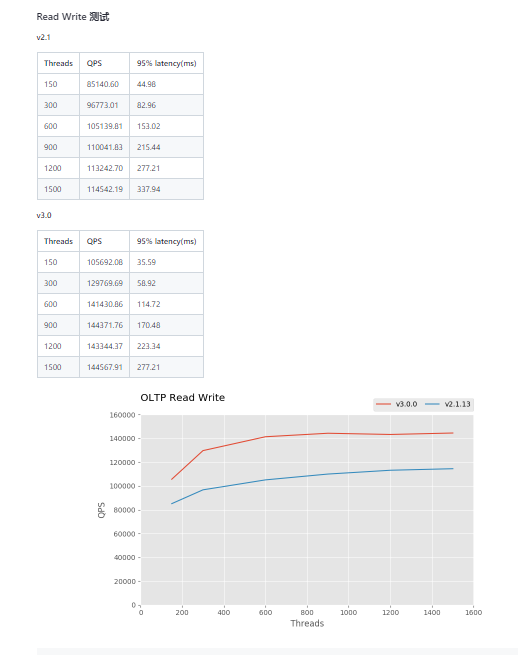
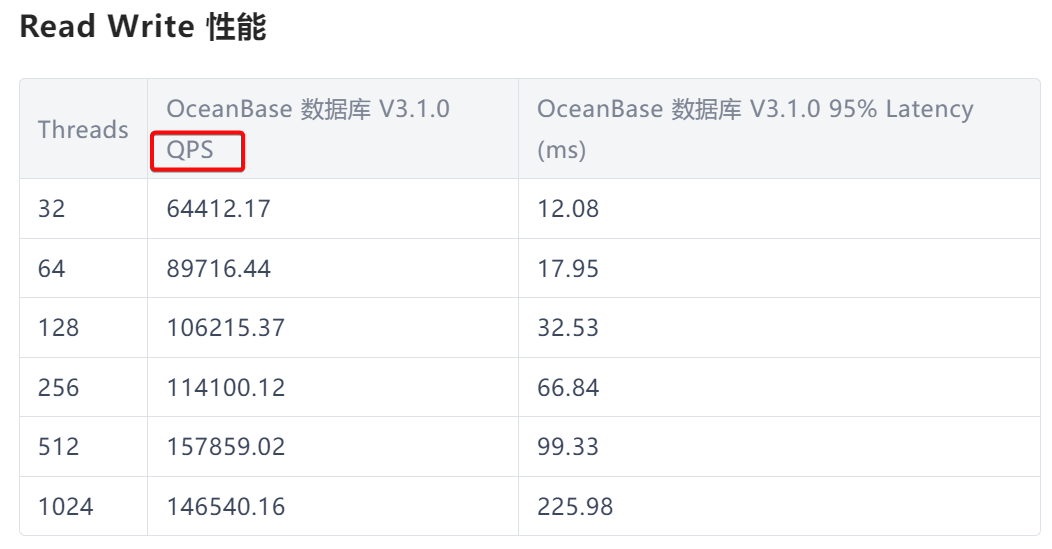
There seems to be a bit of misunderstanding. This test report was conducted by the official team, not by me. It appears that the machine used was directly from TiDB Cloud. The screenshots are directly from the official report. The point query performance is quite good, but the OLTP read-write performance is exceptionally poor. So, is it possible that the official data is incorrect?
It seems like I’ve found the answer. The oltp_read_write test content should be quite complex, with a transaction involving many different operations, which can cause the TPS to be much lower than the QPS.
The official report records the results in TPS, while some previous reports and reports from other sources use QPS.
3.0 test report
That’s right, so when looking at the test report, you need to pay special attention to the horizontal and vertical axes, units of measurement, etc., otherwise, it’s easy to encounter the situation described by the original poster.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.