Streak is a Google Chrome extension that directly integrates with Google Workspace to create a CRM dashboard of sales pipelines, contacts, and action items. Founded in 2011, they now have over 6000 customers worldwide with industry leading companies such as Opendoor, Uber, Atlassian, Logitech, Rappi, and Keller Williams.
Streak is layered on top of Gmail to automatically extract and organize the useful information buried inside of our inboxes. It became clear that they were going to need a better system for organizing terabytes of email metadata to power collaboration as their customer base rapidly increased. After considering multiple options, TiDB is enabling Streak users to share emails and metadata effortlessly and is enabling Streak’s developers to move faster than ever before.
Read on to learn more about Streak’s use cases, challenges, and their reasons for choosing TiDB.
Use Cases
Thread Unification
Streak organizes email data by first applying a unique identifier to the emails and then proactively indexing the email metadata. The unique identifier is what connects the same email headers across inboxes, and thus organizes one thread of communication across multiple users. This results in a large volume of small records – roughly 35 TB of email metadata across the total user base.
Permission Model
Emails can contain sensitive information, whether a password reset or confidential internal messages. That is the reason why email metadata, not the actual email data, is indexed. On top of that, there is a complex permission model applied to ensure that information is shared only to the relevant audience.
Challenges
-
Streak provides their users quick access to filtered and segmented information from their Gmail inboxes. This requires real-time updates and calculations to large volumes of data, particularly as their business grows. They needed a database that performs data analytics in real time, while maintaining high concurrency to ensure their users always receive accurate data.
-
Because Streak indexes every email in a user’s Gmail inbox, they need to store a lot of data. However, the individual records are not utilized evenly – some are highly relevant while others of high volume may be insignificant. This leads to a mismatch between the need for storage and compute nodes. In their search for a database solution, they encountered solutions where the storage and compute nodes must be scaled jointly.
-
Streak processes a large volume of email metadata and often runs into spikes in activity. They need to understand what causes the spikes or hot regions. For example, a widely shared mass email (i.e. a Google terms of service update that is sent to all Gmail users) could cause a write hotspot. They have come across mature database solutions that do not provide enough observability tools to quickly respond to this kind of spike.
-
With roughly 35 TB of data to manage and a lean development team, Streak needs an out-of-the-box database solution that is easy to set up and manage. In the past, they had encountered solutions where the team ended up doing a lot of manual work. For example, some options required manually building indexes or creating a custom backup solution.
-
While their development team is capable of handling database infrastructure tasks, they would rather use their time more efficiently. In order to free up these valuable resources, they realized that customer support from a database solution is crucial to help with set up or day-to-day type of troubleshooting. They had also found that customer support comes at varying levels of knowledge and accessibility – and that inferior customer support can lead to the failure of technical implementation.
Why TiDB
Streak’s team was on the search for a new database solution when they viewed a post on Hacker News about TiDB’s Jepsen test results. They also found TiDB to be ranked high in Github searches for projects compatible with MySQL.
This encouraged the team to try TiDB with a few tables at first. After months of consistent use, they saw how TiDB helped increase performance and reduce latency, improve their developer team productivity, and minimize database infrastructure costs. With TiDB, they found an open-source, distributed, NewSQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads.
Real-time view of strongly consistent data
Streak provides real-time information pulled from multiple Gmail inboxes and organized into user dashboards. The data needs to be updated in real-time and available for multiple users at all times. Initially they tried using Clickhouse, an OLAP database, to index and run analytical queries – followed by pulling the results by key from MySQL. This caused unnecessary manual work for the development team. They became more efficient by using TiDB, a hybrid transactional system that could also run analytical queries (HTAP). Because TiDB is a distributed database, it can spread reads out across multiple TiKV stores and push down computation in parallel. The SQL layer is separated from the storage layer, so heavier analytics workloads can be isolated to a dedicated TiDB server instance.
Streak’s use cases also require strong consistency. It’s key to their customers’ user experience as well as to their own developer team efficiency. The data that customers pull must be accurate – even with simultaneous updates to the same data source. The worst possible scenario would be for stale data to be accidentally written back into the transactional database. TiDB guarantees strong consistency because it is fully ACID-compliant.
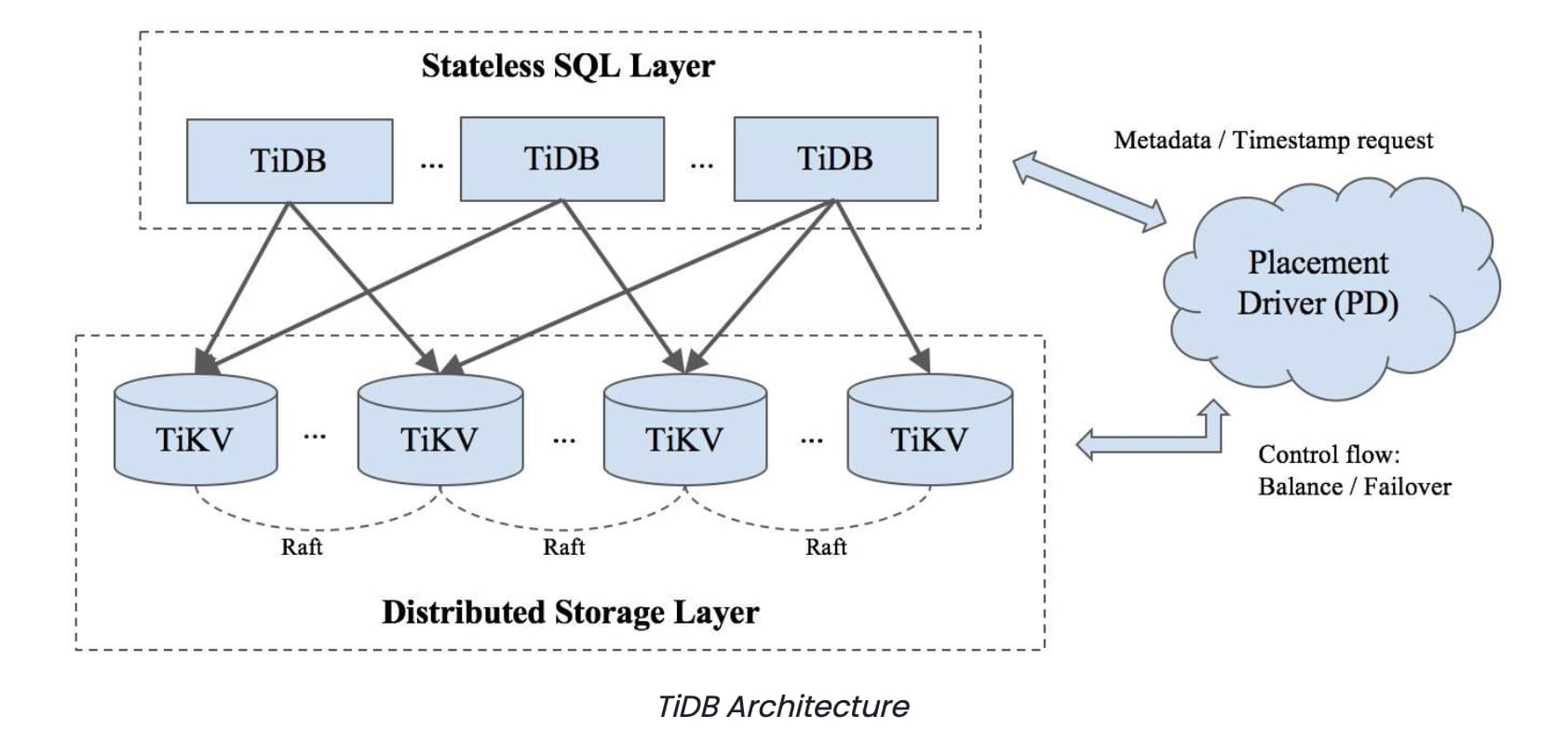
Separate storage and compute nodes
Streak’s distinct use case is that their storage layer and compute layer do not grow at the same speed. This is due to their large index of email metadata, with each record not necessarily being used often or at all. They needed to be able to manage these separately for efficiency and cost reasons. TiDB is able to do this as the architecture is designed to separate computing from storage: TiDB is the stateless SQL compute layer and TiKV is the distributed transactional key-value storage engine. Therefore, one can scale the compute (TiDB) and storage (TiKV) nodes separately to better suit business needs.
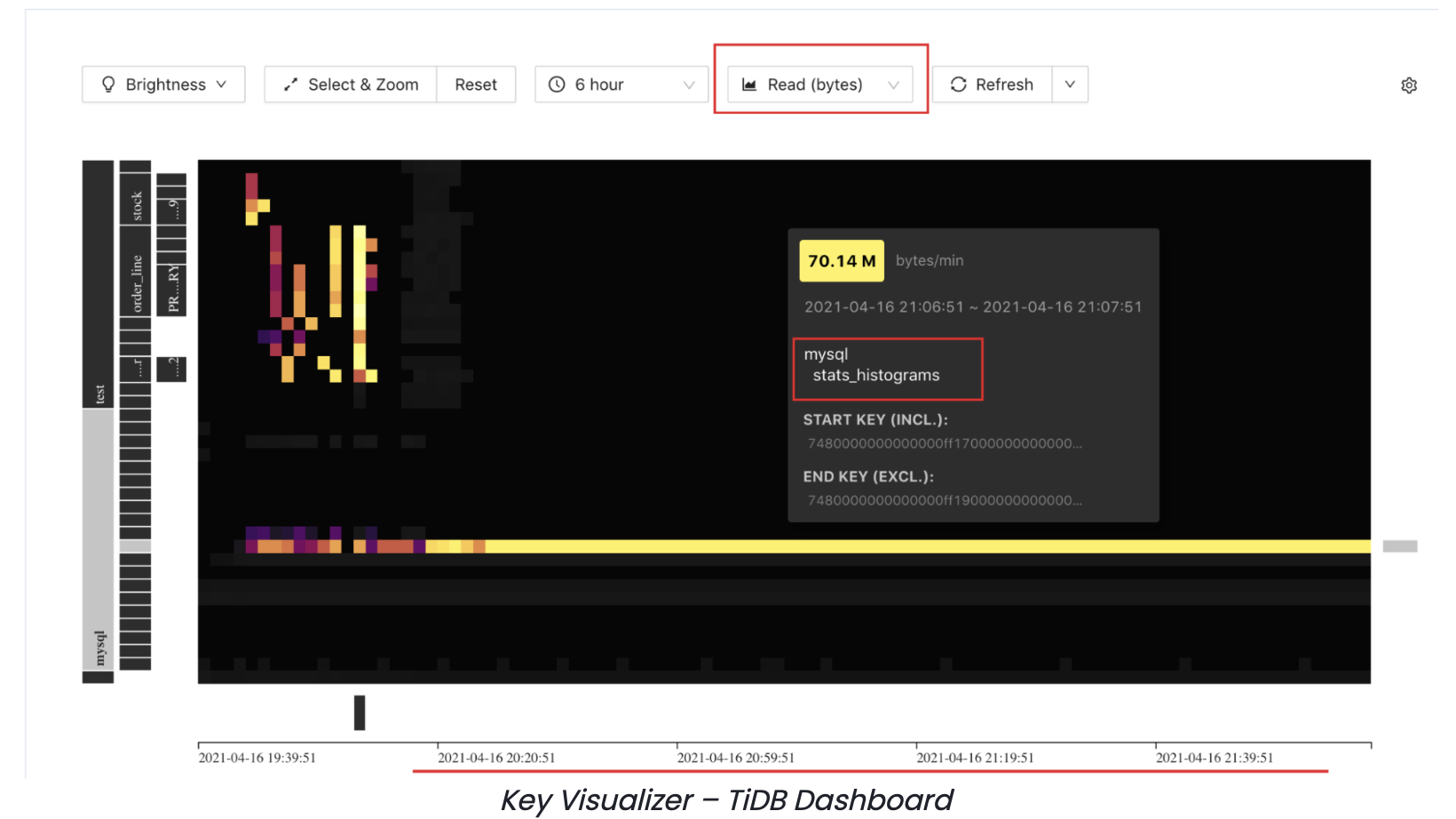
Observability tools for understanding spikes of activity
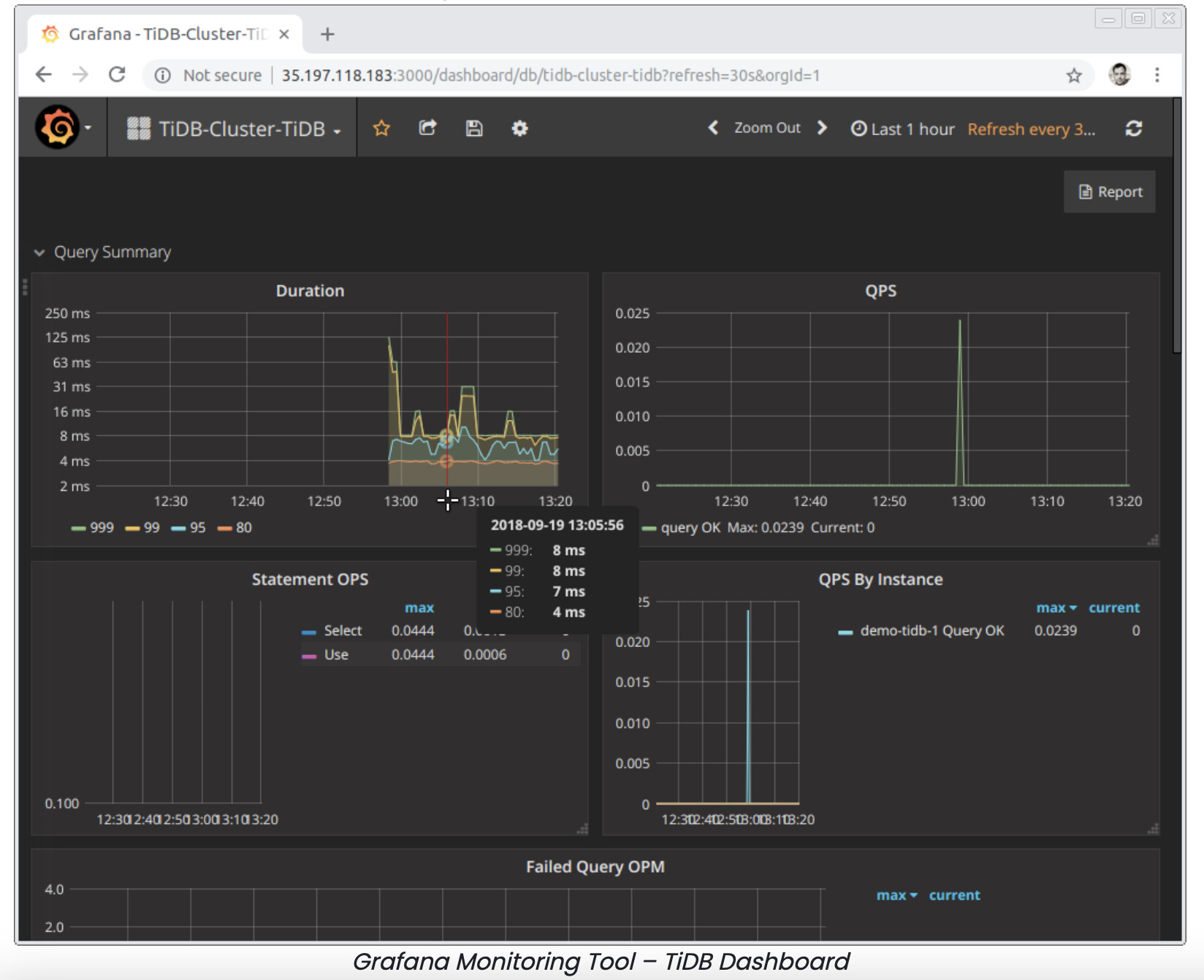
Streak indexes email metadata, and sometimes come across spikes or hot regions with certain indexes. Not only does TiDB have the typical slow query log, but it also has a Key Visualizer tool within the TiDB dashboard. The Key Visualizer analyzes the usage of TiDB and troubleshoots traffic hotspots by visually showing the traffic of TiDB clusters over a period of time. There is also a heatmap that is core to the Key Visualizer which shows the change of a metric over time by plotting it on a XY axis. Different colors indicate the variance in read and write traffic of regions within the time period. The TiDB dashboard also includes a comprehensive set of monitoring tools with Grafana, an open source analytics and interactive visualization web application.
Easy to set up: MySQL compatibility and bulk data migration
Migrating to TiDB was a straightforward experience for Streak because of MySQL compatibility and easy data migration. TiDB is compatible with the MySQL protocol, which makes it easy to migrate from existing MySQL instances.
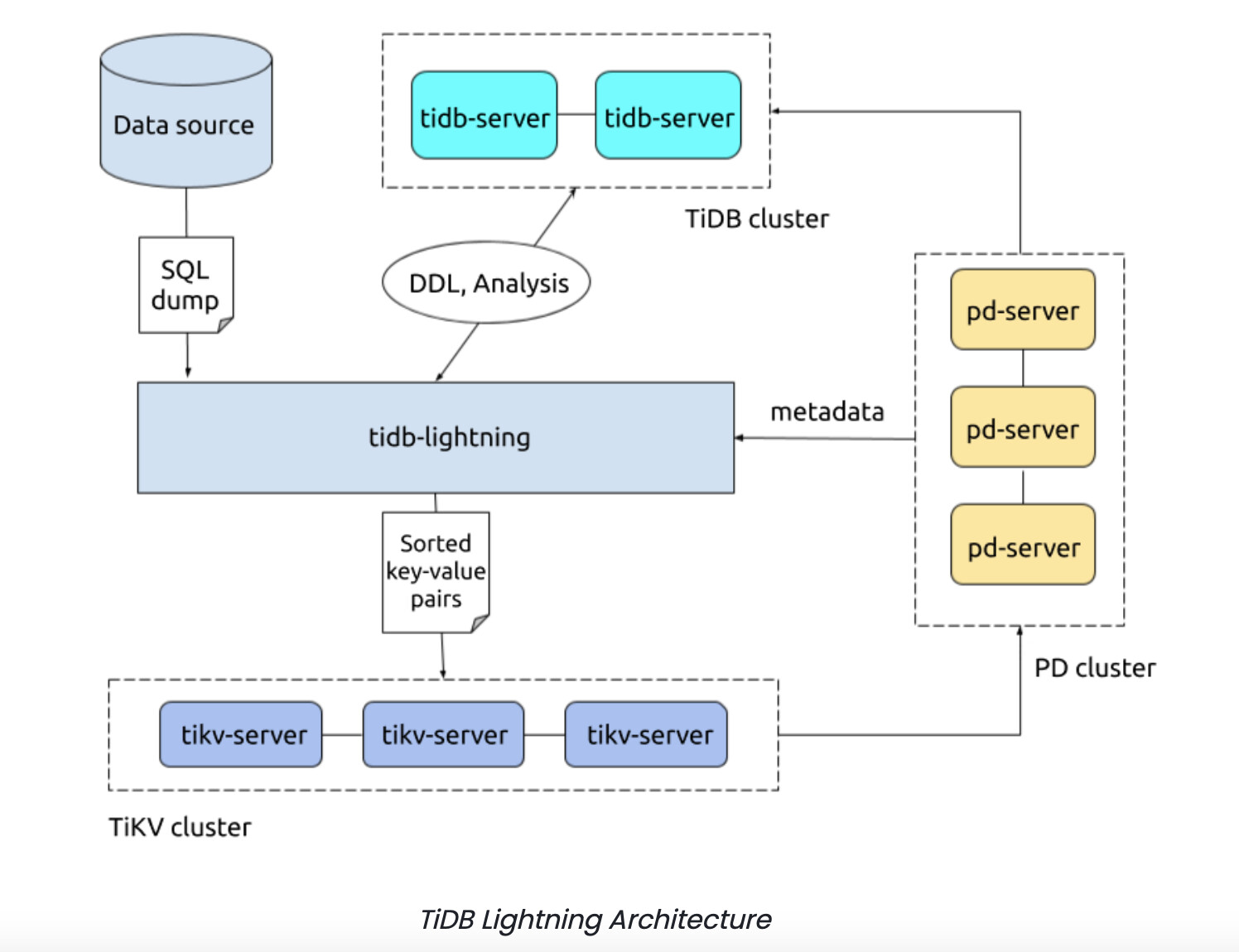
The Streak team migrated data to TiDB using TiDB Lightning, an open source TiDB ecosystem tool that supports fast full-import of a large SQL dump into a TiDB cluster. It is much faster than the traditional “execute each SQL statement” way of importing, at least tripling the import speed to about 250 GB per hour. TiDB Lightning is able to improve the standard import speed by skipping some complicated, time consuming operations.
TiDB Benefits
Before
- Development team spent too much time on manual tasks such as building indexes
- Performance issues without visibility and observability tools to understand root cause
- Costly when scaling – i.e. couldn’t control performance and compute nodes independently
- Insufficient customer support
After
- Single source of truth: real-time view with highly consistent data – no need for manual processes
- Business continuity: built-in high availability and observability tools (Key Visualizer) to deliver performance and self-troubleshooting ability.
- Effortlessly scalable: architecture designed for separate compute and performance layers
- Simple to adopt: MySQL compatible and easy bulk data migration
- Unparalleled 24/7 customer support
Streak is planning to launch a new product feature that will be entirely powered by TiDB in the backend. In the meantime, they are currently migrating data from their datastore to TiDB, with the goal to make TiDB their default database going forward.
![]() Ready to supercharge your data integration with TiDB? Join our Discord community now!
Ready to supercharge your data integration with TiDB? Join our Discord community now! ![]() Connect with fellow data enthusiasts, developers, and experts to: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!
Connect with fellow data enthusiasts, developers, and experts to: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!