Industry: Artificial Intelligence
Authors:
- Mingxing Qu (Architect at PatSnap Data Warehouse Team)
- Liang Li (Senior DBA at PatSnap Data Warehouse Team)
Transcreator: Caitin Chen; Editor: Tom Dewan
PatSnap is a global patent search database that integrates 150 million+ patent data records, 170 million+ chemical structure data records, and thousands of records about financial news, scientific literature, market reports, and investment information. Our users can search, browse, and translate patents, and generate patent analysis reports. We help 10,000+ customers in 50+ countries make better innovation decisions.
As our businesses developed, our data size quickly grew. Previously, we used the Segment + Amazon Redshift data analytics architecture, but it delivered data with poor currency. We needed a data analytical tool that provided more current data. After we compared multiple solutions, we chose the TiDB + Apache Flink real-time data warehouse solution. It is fast and horizontally scalable. Now, we can perform data analytics in minutes and make faster and wiser business decisions.
In this post, we’ll share why we adopted TiDB + Flink, how we use this data warehouse, and what benefits it brings us.
Our pain points
As our businesses develop and our users quickly grow, during business operations, we deeply rely on real-time data analytics and result reports to analyze user behaviors. We need real-time market data, operational data for specific scenarios, and traffic and service analysis.
Originally, we used the Segment + Amazon Redshift data analytics architecture and only built the operational data store (ODS) layer. We couldn’t control data write rules and schemas. In addition, we needed to write complex extract-transform-load (ETL) job scripts for ODS. To complete data requests from upper-level applications, we needed to calculate various metrics based on application requirements. Redshift stored a large amount of data, and it calculated data slowly. This lowered external service efficiency.
Why we chose the TiDB + Flink real-time data warehouse
After we compared multiple solutions, we decided to use the TiDB + Flink real-time data warehouse solution to improve our data analytical capabilities.
TiDB is an open-source, distributed, Hybrid Transactional/Analytical Processing (HTAP) database. It’s a one-stop solution for both Online Transactional Processing (OLTP) and Online Analytical Processing (OLAP) workloads. TiDB’s architecture integrates row storage and column storage. Its storage uses separated nodes to ensure that OLTP and OLAP workloads don’t interfere with each other.
Apache Flink is a big data computing engine with low latency, high throughput, and unified stream- and batch-processing. It is widely used in scenarios with high real-time computing requirements and provides exactly-once semantics.
Combining TiDB and Flink into a real-time data warehouse has these advantages:
- Fast speed. You can process streaming data in seconds and perform real-time data analytics.
- Horizontal scalability. You can increase computing power by adding nodes to both Flink and TiDB.
- High availability. With TiDB, if an instance fails, the cluster service is unaffected, and the data remains complete and available. Flink supports multiple backup and restore measures for jobs or instances.
- Low learning and configuration costs. TiDB is highly compatible with the MySQL protocol. In Flink 1.11, you can use the Flink SQL syntax and powerful connectors to write and submit tasks.
How we use TiDB + Flink
When we replaced our Segment + Redshift architecture with Kinesis + Flink + TiDB, we found that we didn’t need to build an ODS layer in the database, but just in Amazon Simple Storage Service (S3) storage.
As a precomputing unit, Flink builds a Flink ETL job for the application. This fully controls data saving rules and customizes the schema; that is, it only cleans the metrics that the application focuses on and writes them into TiDB for analytics and queries.
We build three layers on top of TiDB: data warehouse detail (DWD), data warehouse service (DWS), and analytical data store (ADS). These layers serve application statistics and list requirements. They are based on user, tenant, region, and application metrics, as well as time windows of minutes or days. The upper application can directly use the constructed data and perform real-time analytics within seconds.
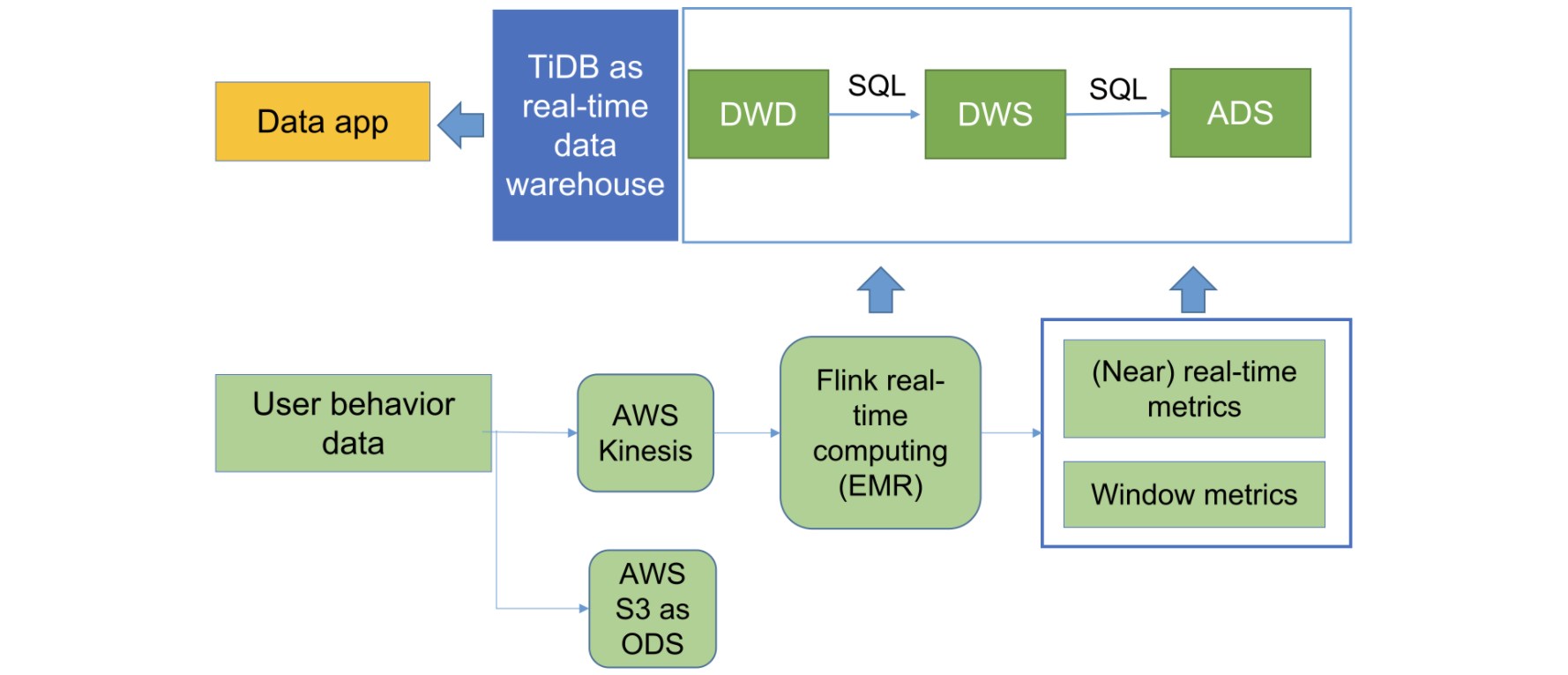
PatSnap data analytics platform architecture
This real-time analytical platform architecture realizes truly real-time data as a service. We use it to analyze and track user behaviors and analyze tenant behaviors in real time. It provides real-time data support for our business operations.
How we benefit from TiDB + Flink
After we adopted the TiDB + Flink architecture, we found that:
- Inbound data, inbound rules, and computational complexity are greatly reduced.
- Queries, updates, and writes are much faster.
- Reasonable data layering greatly simplifies the TiDB-based real-time data warehouse, and makes development, scaling, and maintenance easier. Our query performance for complex reports remarkably increases. In many application scenarios, our queries’ data currency greatly improves. Previously, after some data was generated, it took one day to retrieve queries for business use. But now, they are near real time for analytics.
- This solution meets requirements for different ad hoc queries, and we don’t need to wait for Redshift precompilation.
If you want to know more details about our story or have any questions, you’re welcome to join the TiDB community on Slack and send your feedback.
![]() Ready to supercharge your data integration with TiDB? Join our Discord community now!
Ready to supercharge your data integration with TiDB? Join our Discord community now! ![]() Connect with fellow data enthusiasts, developers, and experts to: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!
Connect with fellow data enthusiasts, developers, and experts to: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!