Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 6.1.2 升级 6.5.2 后写入耗时翻倍
[TiDB Usage Environment] Production Environment
[TiDB Version] 6.5.2
[Reproduction Path] Upgrade from 6.1.2 to 6.5.2
[Encountered Problem: Phenomenon and Impact]
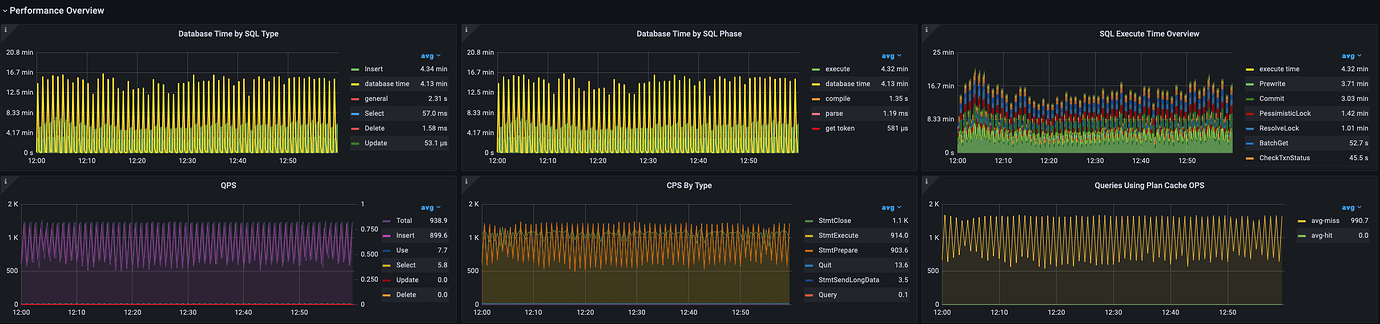
Before Upgrade
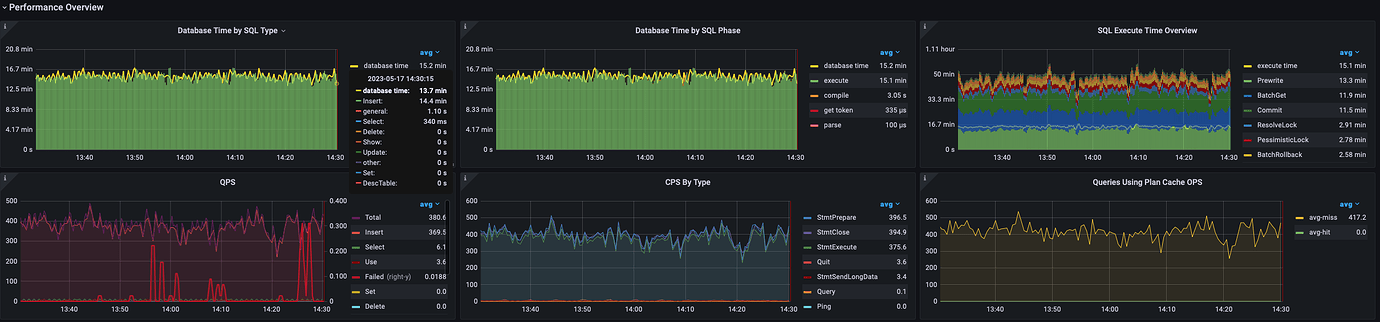
After Upgrade
[Resource Configuration]
If the cluster configurations are exactly the same, it is best to find a detailed scenario for comparison, such as:
- Same structure
- Same number of rows and column information written
- What the differences in writing are like
- Additionally, you can supplement with a comparison of the write execution plans
- You can also check for hardware differences in terms of IO
This difference is quite significant…
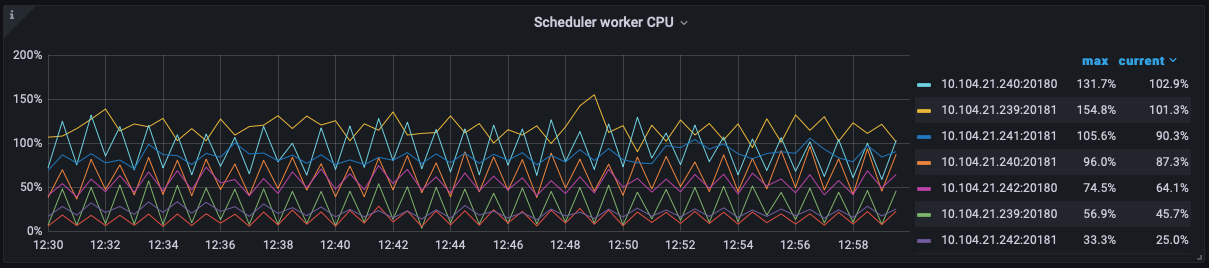
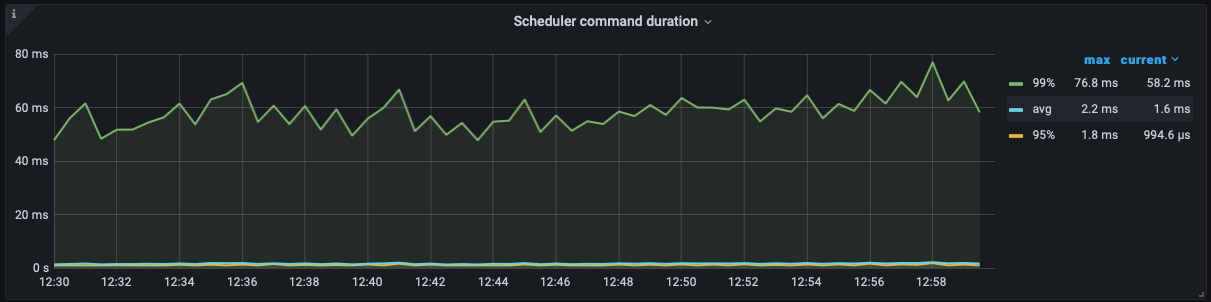
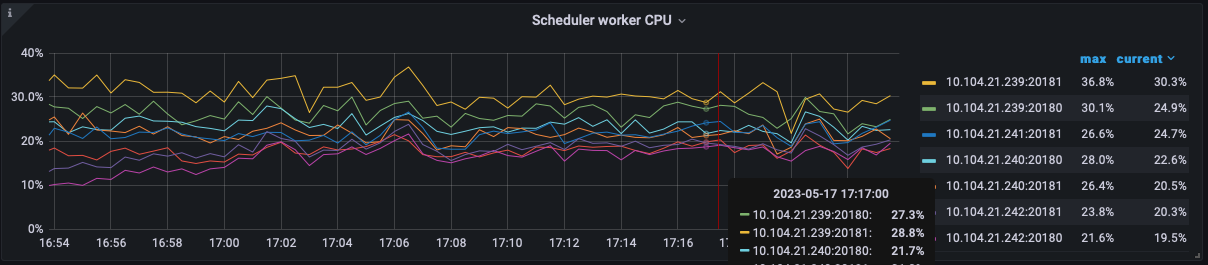
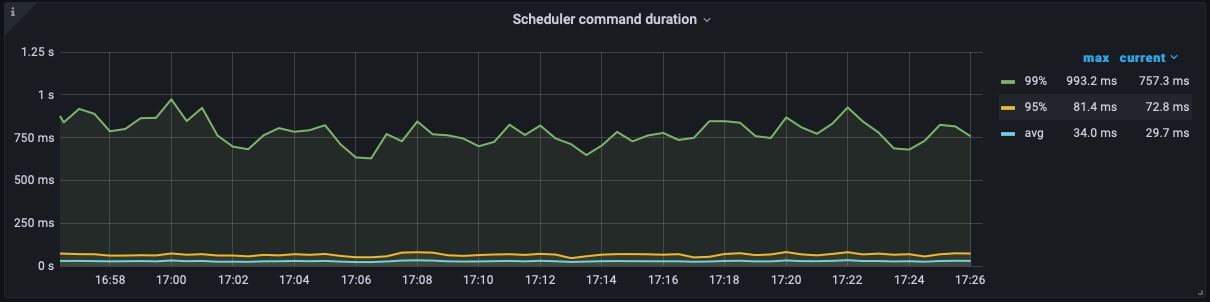
The BatchGet of Scheduler is much slower than before the upgrade, but the Thread CPU doesn’t seem to be very high.
Before the upgrade:
After the upgrade:
According to the direction mentioned in 读性能慢-总纲 - TiDB 的问答社区, check and see which part is the problem.
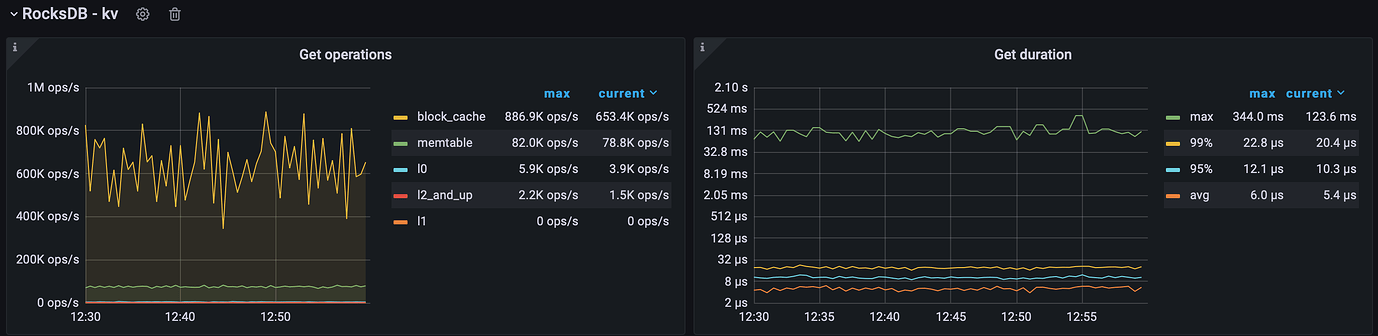
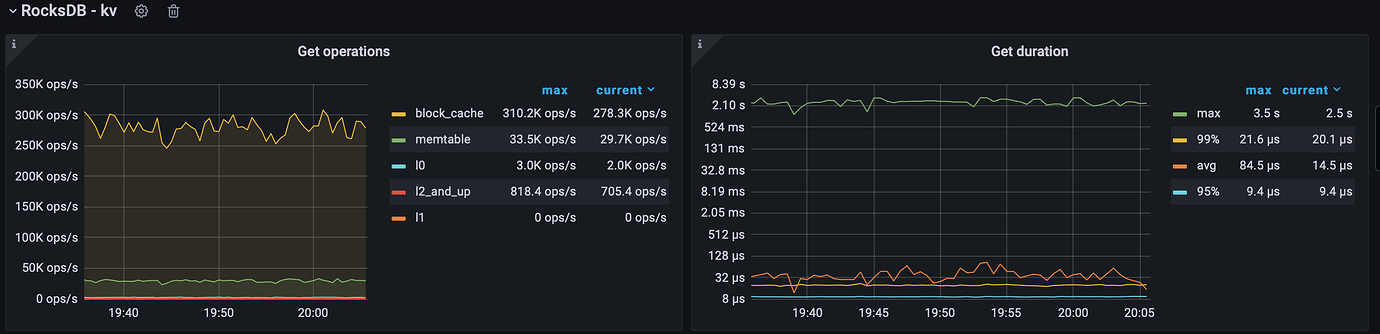
Thank you for providing the troubleshooting direction. Following the main outline, it was found that there is a phenomenon of extremely high long-tail latency in RocksDB’s Get operation.
Before the upgrade:
After the upgrade:
The hit rate has decreased, and the query has slowed down…
You can refer to these metrics for further investigation:
However, I suggest finding a single table with relatively frequent business operations and try to fetch data through the primary key to see how long it takes to execute. Then, check the number of MVCC versions in the execution plan…
It shouldn’t be a load issue because performance dropped significantly after the upgrade, causing write timeouts. Subsequently, a large number of writes were discarded, and the insert QPS was halved.
The other cluster with dual writes is still on v6.1.2, and its performance has been stable with a low load.
The writes being executed are all of this type:
INSERT INTO XX ON DUPLICATE KEY UPDATE
It’s frustrating that we can’t roll back after the upgrade…
Before a major version upgrade, it’s better to do a POC, this way you’ll be more confident.
Minor version changes are smaller, mainly focusing on fixes.
There are also those using version 4.X.X who never upgrade because it’s very stable… 
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.