Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 作业帮 x TiDB | 多元化海量数据业务的支撑
Author: Liu Qiang @是我的海, Data Architect and Distributed Database Leader at Zuoyebang
Zuoyebang, an online education brand established in 2015, is committed to using technology to promote educational equity. Over nearly a decade, Zuoyebang has utilized AI, big data, and other technologies to provide learning and educational solutions, smart hardware products, and more for students, teachers, and parents. As the company’s products and business scenarios have become increasingly diverse, the volume of data has grown, and the demand for database usage has become more varied. This article introduces the exploration journey of TiDB at Zuoyebang and its gradual implementation in multiple business scenarios.

This article is excerpted from the TiDB New Year Tea Party on January 7, 2024.
Presentation Video
I. Exploration and Promotion of TiDB at Zuoyebang
The initial version of TiDB that Zuoyebang encountered was TiDB v4.0.9. Compared to TiDB v3.x, v4.0.9 had significant improvements in performance, management, and ease of use. Additionally, TiDB’s ecosystem components and community had reached a very mature level, making it a landmark version. In 2020, we officially began researching and testing TiDB v4.0.9 to build our team’s technical reserves in distributed databases, thereby better serving the company’s business needs.
1. Exploration Phase: Using TiDB to Isolate Query Requests Affecting Online MySQL Clusters
R&D personnel need to query real-time online data from time to time to determine business data conditions or perform summary analysis on some business data.
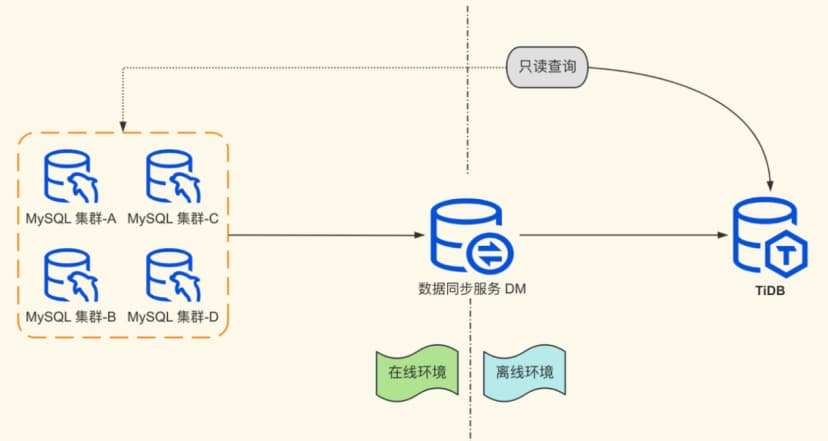
Before introducing TiDB: Business personnel directly connected to the MySQL replica to query data. If the data volume scanned was too large, it often caused performance fluctuations in the online MySQL nodes or even resource bottlenecks in IO/CPU.
After introducing TiDB: Using the data synchronization tool DM, MySQL data was synchronized to TiDB in a full + real-time incremental manner, achieving isolation of online and offline requests.
In this exploration phase, we met the requirement for offline query isolation and became familiar with the features and usage of TiDB and its ecosystem components.
2. Promotion Phase: Internal Sharing + Proactive Engagement
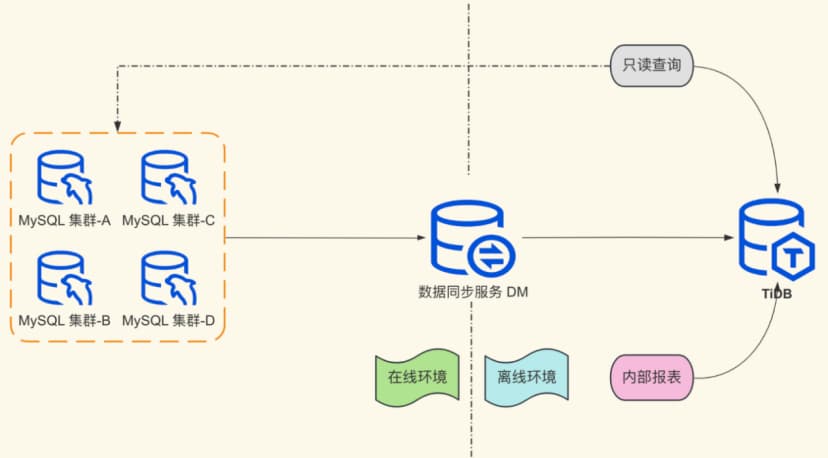
After about six months of use and gaining a certain understanding of TiDB, we began to share TiDB-related technologies within the company, introducing R&D personnel to some features of TiDB and its advantages in large data volume scenarios. We also proactively contacted various business lines to find suitable usage scenarios. R&D personnel gradually connected some internal report services to the offline TiDB cluster.
II. From 0 to 1 in Online Business Implementation
After various teams used and became familiar with TiDB for a period, we began to focus on TiDB for existing business pain points or future new business plans. By collaborating with the business to test and verify, we officially started migrating online business to TiDB.
1. Using TiDB to Break Through Storage & Performance Bottlenecks in the Reporting Platform
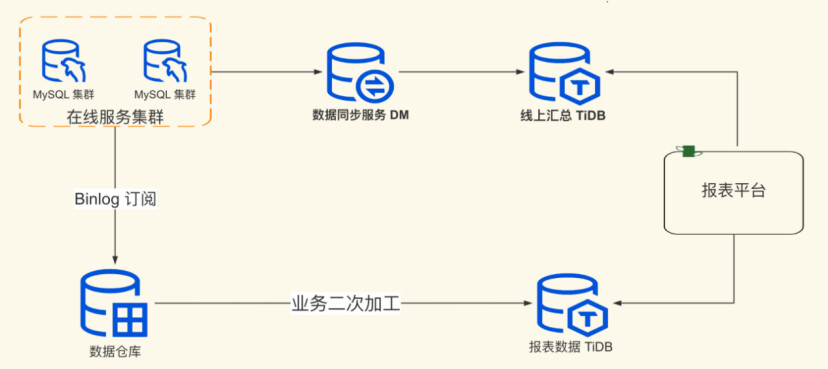
Zuoyebang’s reporting service imports a large amount of file data from various business lines daily to achieve the final data dashboard display. As the number of business lines increased and the disk limitations of single MySQL instances became apparent, the reporting service platform gradually exhibited storage limitations and slow data display responses, even to the point of being unresponsive.
We synchronized data to TiDB using DM. After business verification, TiDB achieved high compatibility with SQL. Compared to the time taken using MySQL, TiDB reduced the time by 80%, far exceeding expectations. As DM synchronization stability improved, the reporting platform also switched some report services that directly connected to online MySQL to use TiDB as the data source.
After the transformation, the final architecture of the reporting service is as follows:
2. Business Transaction Data
The main characteristics of business transaction data are the large daily data write volume and the need for long-term storage. In multiple business lines within the company, as long as they reach a certain stage of development, using MySQL for data storage will eventually encounter storage bottlenecks. At this point, TiDB becomes an excellent solution.
III. From 1 to N in Online Business Implementation
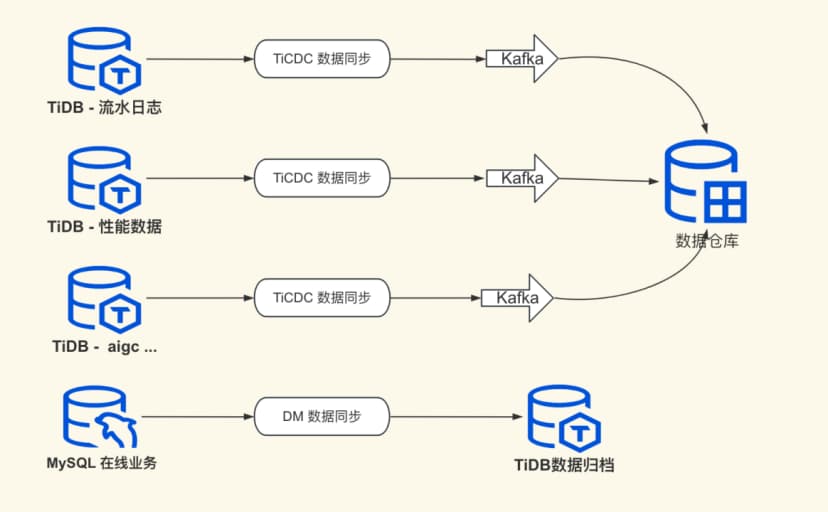
Thanks to the reliability of DM data synchronization and the compatibility and stability of later TiDB-5.x versions, some businesses at Zuoyebang gradually migrated performance collection data, user access records, business logs, and other businesses to TiDB. Additionally, in the context of the AI explosion, more exploratory businesses naturally require storing massive amounts of data, making TiDB the preferred solution. Of course, many core businesses online will not easily change their data storage solutions, so using TiDB for historical data archiving is also the current standard solution.
Starting from TiDB 4.0, TiDB introduced the TiFlash columnar storage engine, which has been continuously enhanced in subsequent versions. If a business has any complex query requirements, it can directly solve some complex queries by adding TiFlash nodes in the TiDB cluster.
IV. Summary and Future Outlook
Now, TiDB can stand on its own in Zuoyebang’s internal usage. Currently, Zuoyebang has deployed dozens of TiDB clusters, with a total data volume exceeding hundreds of TB. Most of these clusters use TiDB 5.4, and half have been upgraded to version 6.5. If you are still using version v3.x, it is recommended to test upgrading to the new version using some safe methods. Zuoyebang has continuously upgraded from version v4.0.9, and the overall experience is increasingly stable, reassuring, and the upgrade process is very smooth, with almost no business perception.
Recently, I saw news that Hangzhou Bank has launched TiDB 6.5.6 in its core accounting system. By next year, we should also upgrade to this version entirely.
Finally, some hopes for TiDB:
Hope TiDB can have a primary-backup cluster solution that does not rely on CDC, which can be used for disaster recovery in different data centers and as an upgrade rollback solution to avoid business incompatibility after upgrades;
Explore using resource control solutions. For MySQL sharding businesses, it is impossible to synchronize multiple sub-clusters to the same TiDB cluster, as there will be database name conflicts;
SQL rate limiting or interception function: For SQLs with abnormally high resource consumption, it can automatically downgrade to avoid exhausting cluster resources and causing a cluster avalanche.
